
我發現老師上課教的購物籃分析跟一般普遍認知的「購物籃分析」不太一樣。
一般的購物籃分析是看同次購買,老師的則是看不同次之間。我打算兩種都做,最後再看哪種比較適合。
多次交易之間
老師教的購物欄分析總共有以下矩陣:
Correlation Matrix(相關係數矩陣)
Factor Loading Matrix(因素負荷量矩陣)
Conditional Probability Matrix(條件機率矩陣)
Conditional Purchase Timing Matrix(條件購買期間矩陣)
因素分析是用於資料縮減,但由於我的 Demo 裡商品只有 10 項,所以就不做因素分析。
整理資料
我需要一筆一筆分開的訂單紀錄,並且我一樣只用前半段的資料來做。所以我先複製「前段_展開」工作表和「後段_展開」工作表。
接著我要清掉不會用到的欄位。
只留下訂單 ID、日期、顧客 ID、商品、商品單價(在這個範例資料裡,每筆訂單中每個商品最多被購買一件)。
後段也做同款整理。
相關係數矩陣
我要來做相關係數矩陣,首先使用前段的訂單資料插入一個樞紐分析表。欄用 item,列用 order_id,值是 item 的計數。
我把樞紐表的值複製到新的工作表,並刪掉總計欄、總計列。
接著我要將空白處補 0 並將多筆以上資料改為 1(雖然因為我這資料每個商品一張訂單最多被購買一次,所以不會有超過 1 的值)。
=IF(工作表3!B2>=1,1,0)我複製出一個新工作表,在第一格填入此公式並拉開。
相關分析
然後要用剛剛那個工作表做相關矩陣,我試試看用 Claude Cowork 操作 Insyra CLI 來做。
幫我用最新版的Insyra CLI 用 工作表4 做商品*商品的相關係數矩陣 存成CSV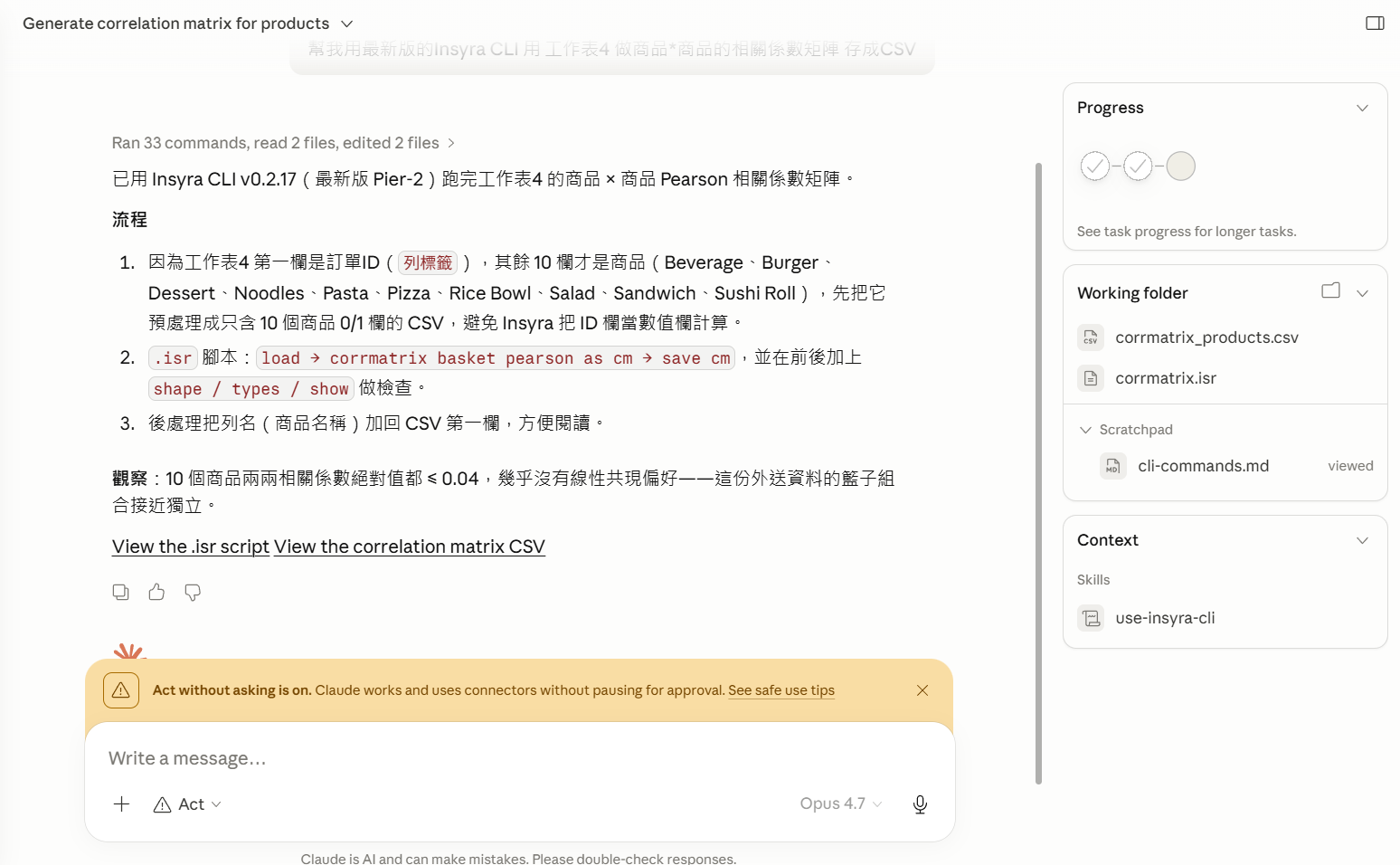
我把矩陣複製進 Excel。
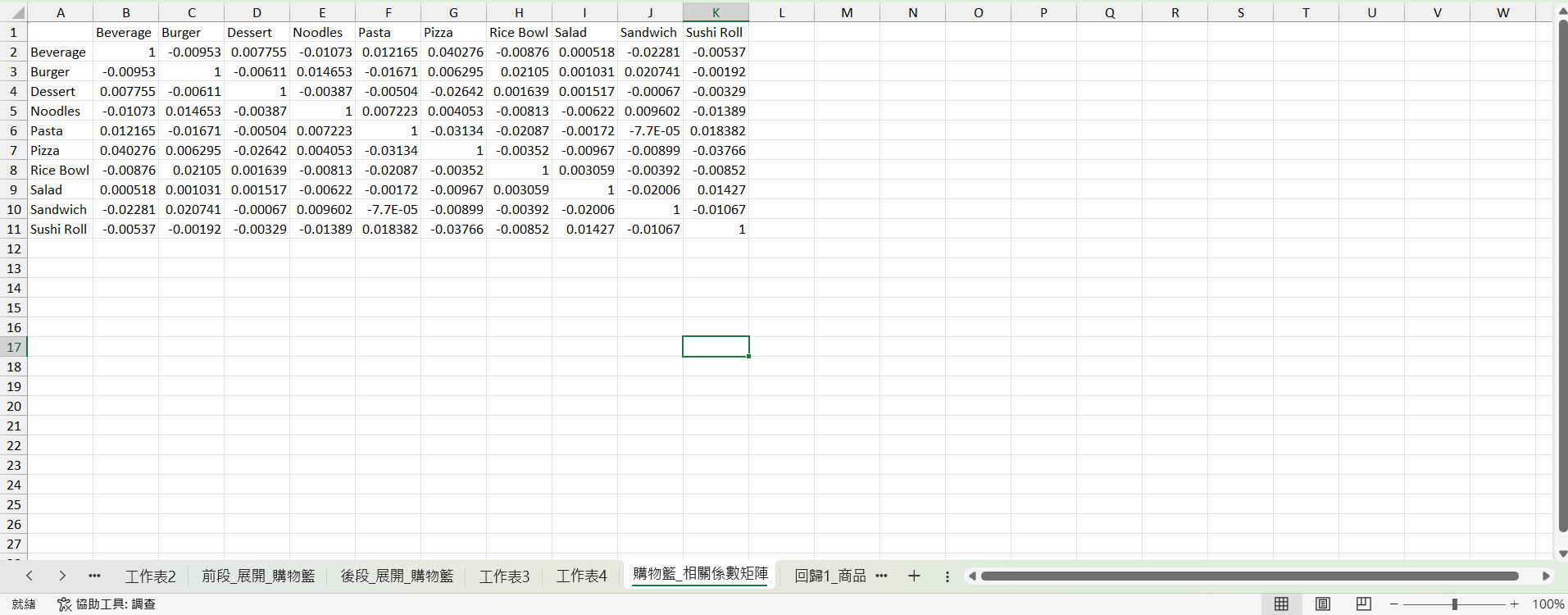
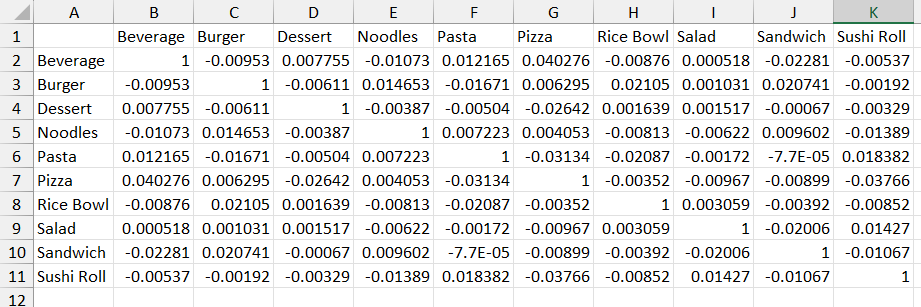
我還順便叫他用 Python 驗證一下,哈哈。
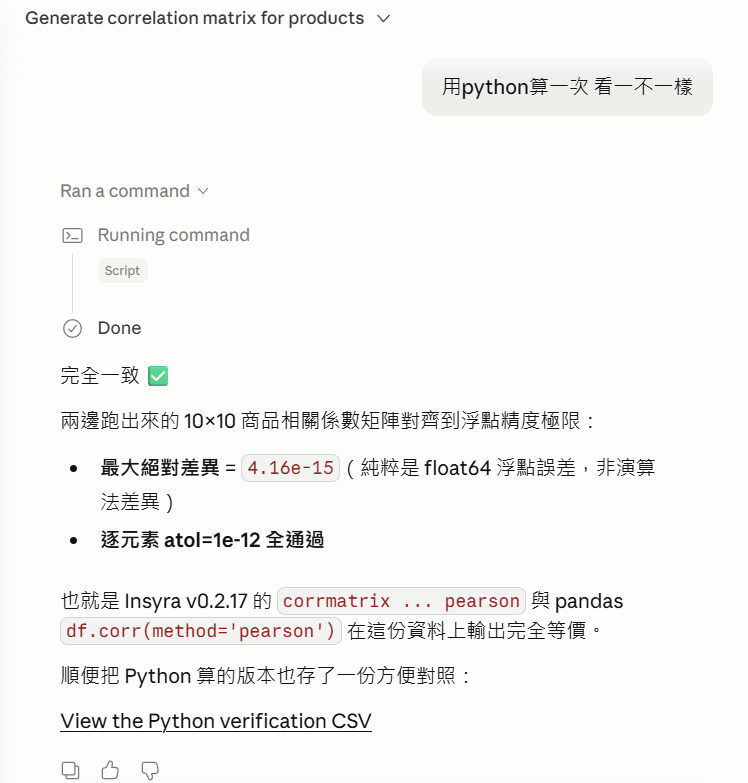
看起來 Insyra 算的準確無誤!
條件機率矩陣
在做條件機率矩陣時,為簡化起見,假設每位客戶一天中只有一筆交易記錄。所以每一人每一天只留一筆交易紀錄。
我複製 前段_展開_購物籃 那張表來做簡化。
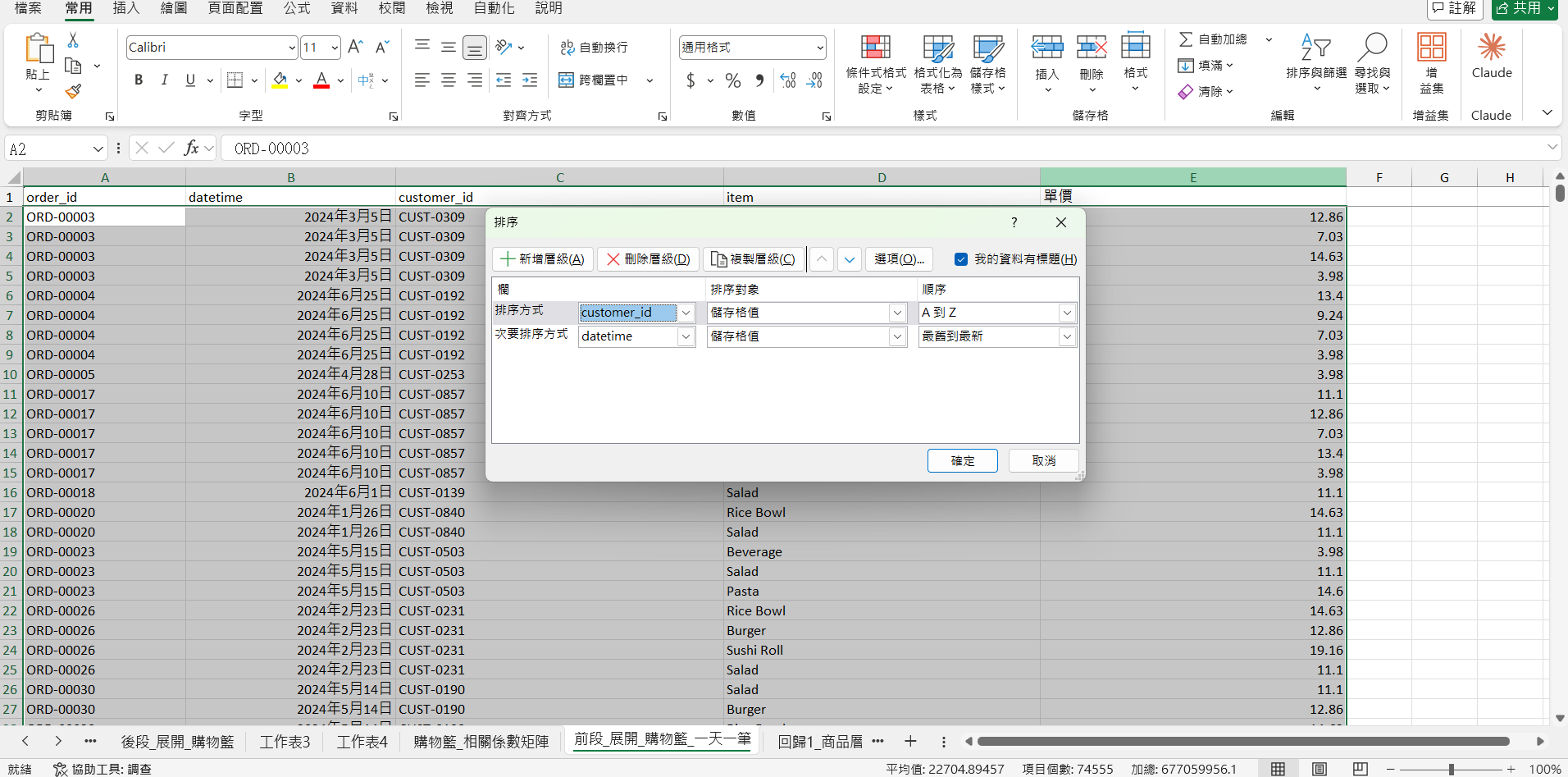
先做排序,依據 顧客ID -> 日期 來排。然後請 Claude 幫我一個人同一天只留第一筆。
在 前段_展開_購物籃_一天一筆 表 幫我同一個人同一天只留第一筆完成。原本 14,910 列,刪掉 196 列(屬於同人同日的後續訂單),保留 14,714 列。
判定邏輯:用 customer_id + 日期datetime 取整數天)分組,保留每組第一個出現的 order_id,該訂單的所有品項列都保留;同人同日後續訂單的所有列都刪除。
他有點太貼心但我們要刪到同個人同一天只留第一個品項。
只保留同個人同一天第一個品項完成。表內現在每個 customer_id + 日期只剩一列(第一個品項),共 4,199 列資料。
注意:由於先前那次超時,原本同人同日的「第一筆訂單第一個品項」可能已經被部分刪除過,所以結果是基於當時表內剩餘的資料去重得到的。如果想要從最原始的 14,910 列重新做一次「同人同日只留第一個品項」,需要從來源表(例如 [前段_展開_購物籃](<citation:前段_展開_購物籃>))重新生成這張表 — 要我重做嗎?
轉換成移轉次數矩陣
接著我插入一個 item_next 欄,放該顧客下一次購買的品項。
=IF(C3=C2,D3,9999)9999 表示沒有下一次(該次交易為該顧客最後一次)。
開一個樞紐表,欄放 item、列放 item_next、值放 order_id 的計數。
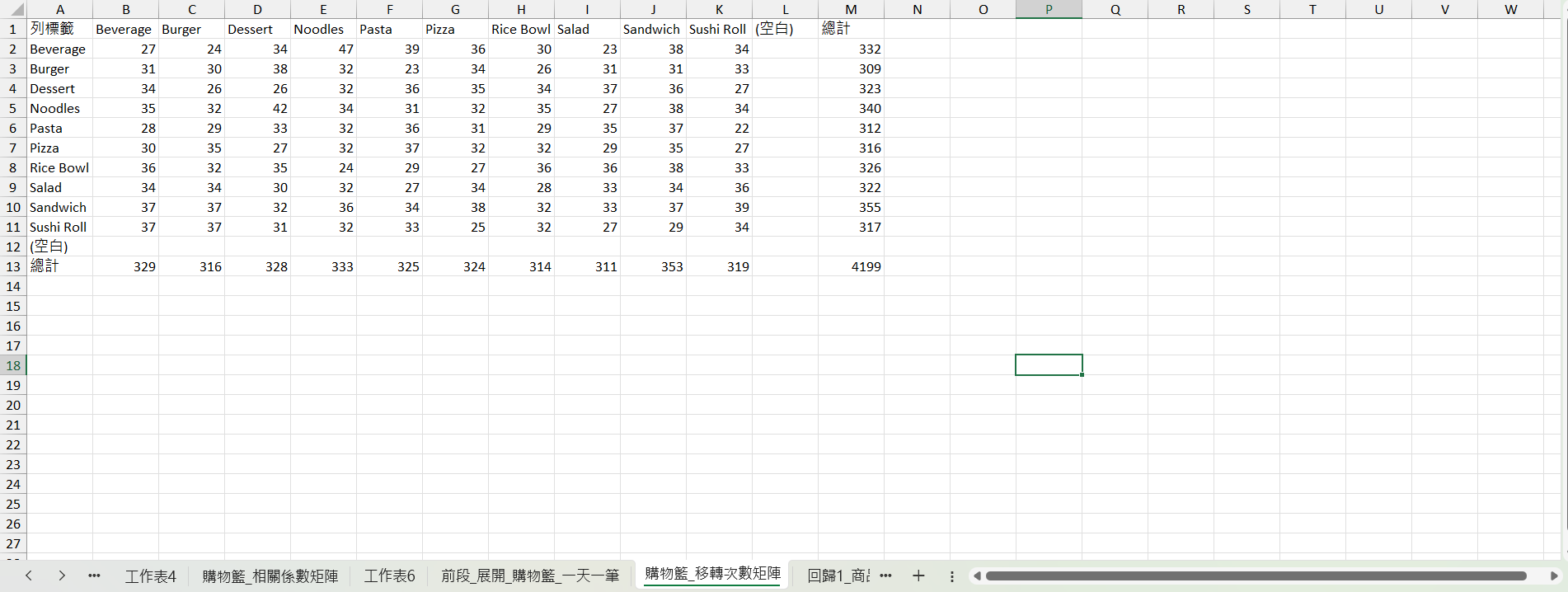
把樞紐表的值複製一份,刪掉 9999,總計重算,這就是移轉次數矩陣。
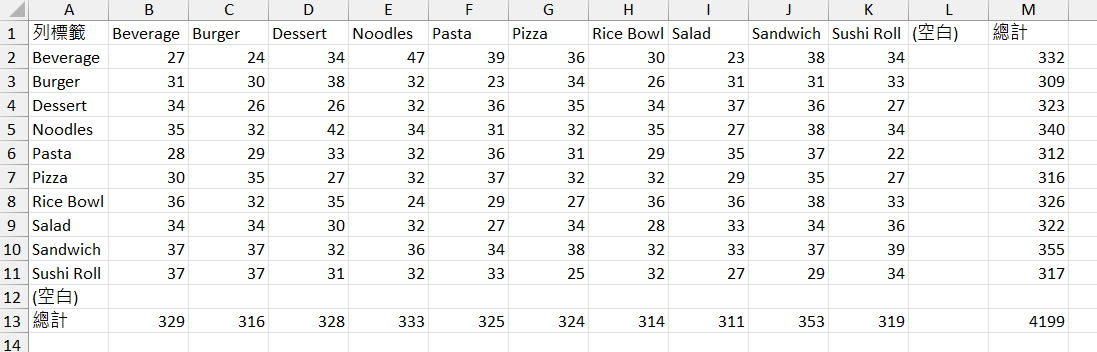
計算條件機率矩陣
條件機率矩陣就是 值/總計。
=購物籃_移轉次數矩陣!B2/購物籃_移轉次數矩陣!B$13
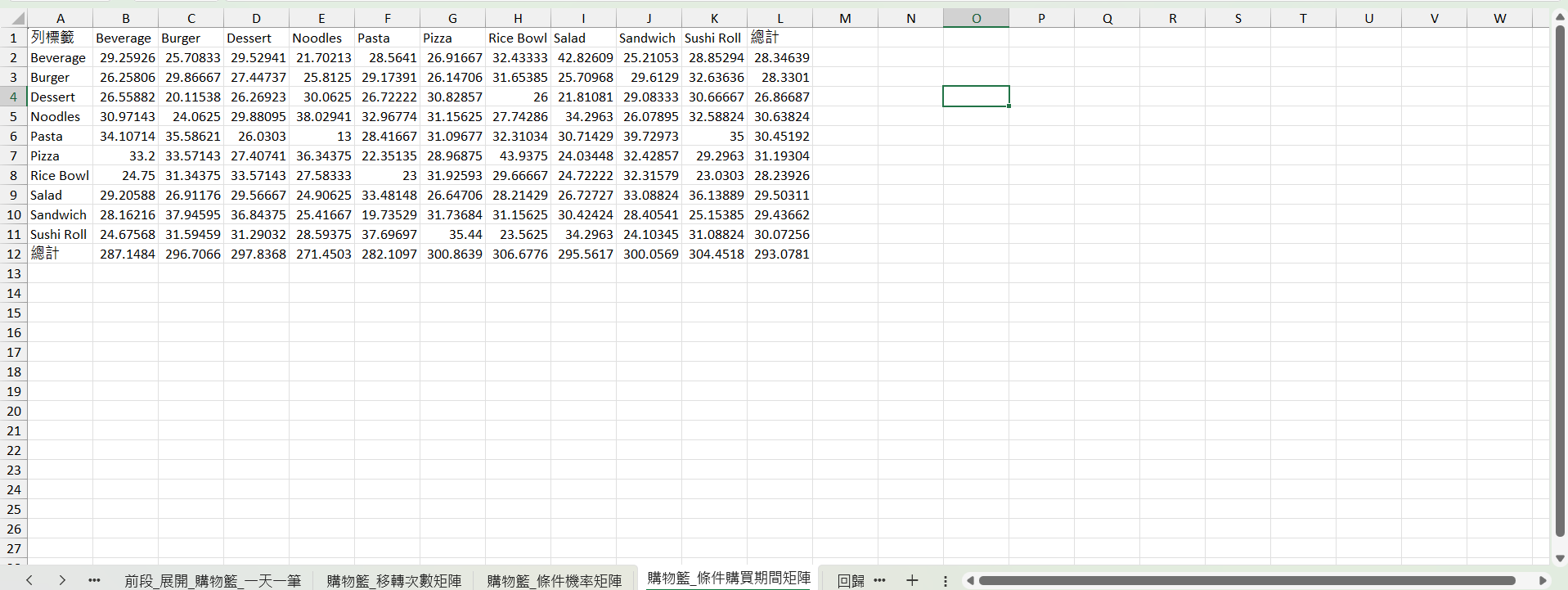
條件購買期間矩陣
條件購買期間矩陣是看這次購買 A 商品後,平均多久後會購買 B 商品。
首先要新增一欄 間隔天數 指的是該顧客這次消費和下一次之間隔了幾天。
=IF(D3=D2,DAYS(B3,B2),"")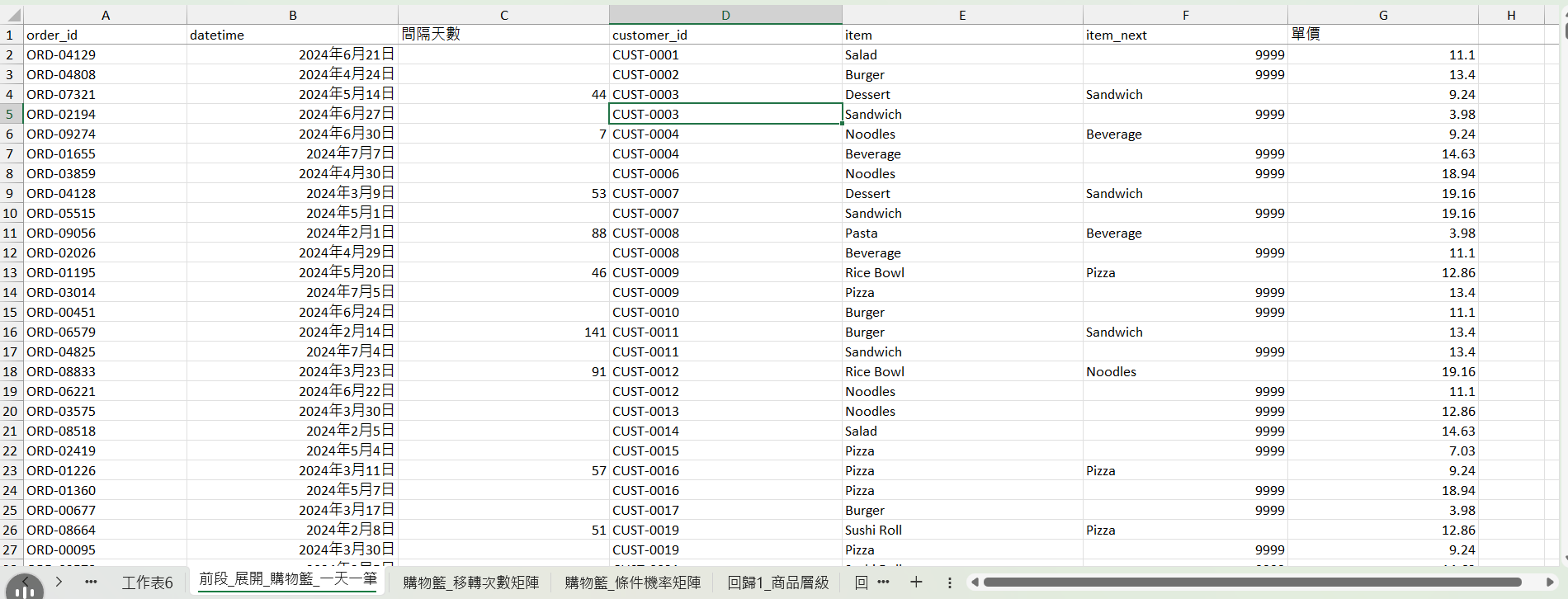
然後插入樞紐分析表,欄放 item,列放 item_next,值放 間隔天數的平均值。
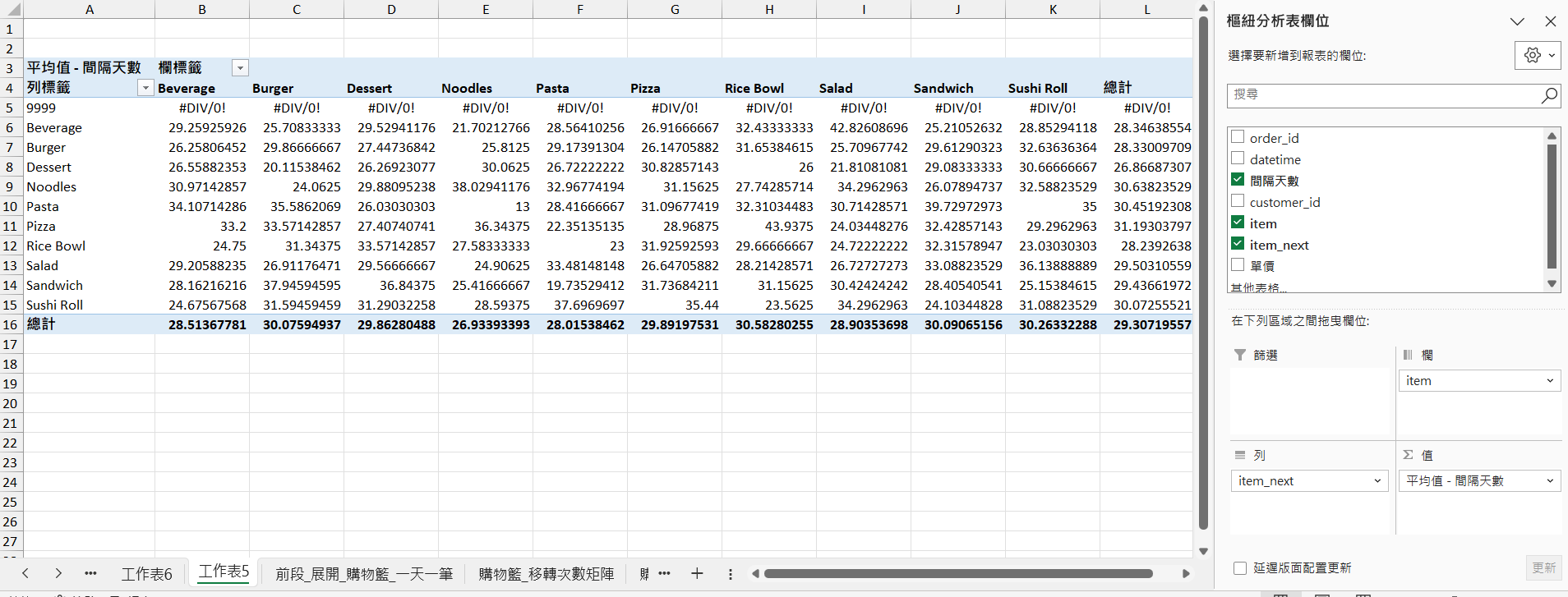
值貼上到新的表,刪掉 9999 然後重算總計,這就是條件購買期間矩陣。
驗證
三個矩陣都建立在「前段」資料上,要驗證它們對「後段」的預測力,核心邏輯是:
用前段建立的規則,去預測後段每位顧客「下一個會買什麼/何時買」,再跟後段實際發生的對照。
三種矩陣的預測含義與驗證設計
Claude 建議的具體做法(在新的「驗證」分頁做)
Step 1:在後段建構「下一筆」配對表 從 後段_展開_購物籃 衍生兩種視角:
同單共現:以 order_id 分組,列出每張單的商品集合(驗證相關係數用)
顧客序列:以 customer_id 排序 datetime,每筆配上同顧客的「下一筆 item」與「下一筆 datetime - 當筆 datetime」(驗證條件機率 + 條件購買期間)
Step 2:對三個矩陣分別計算驗證指標
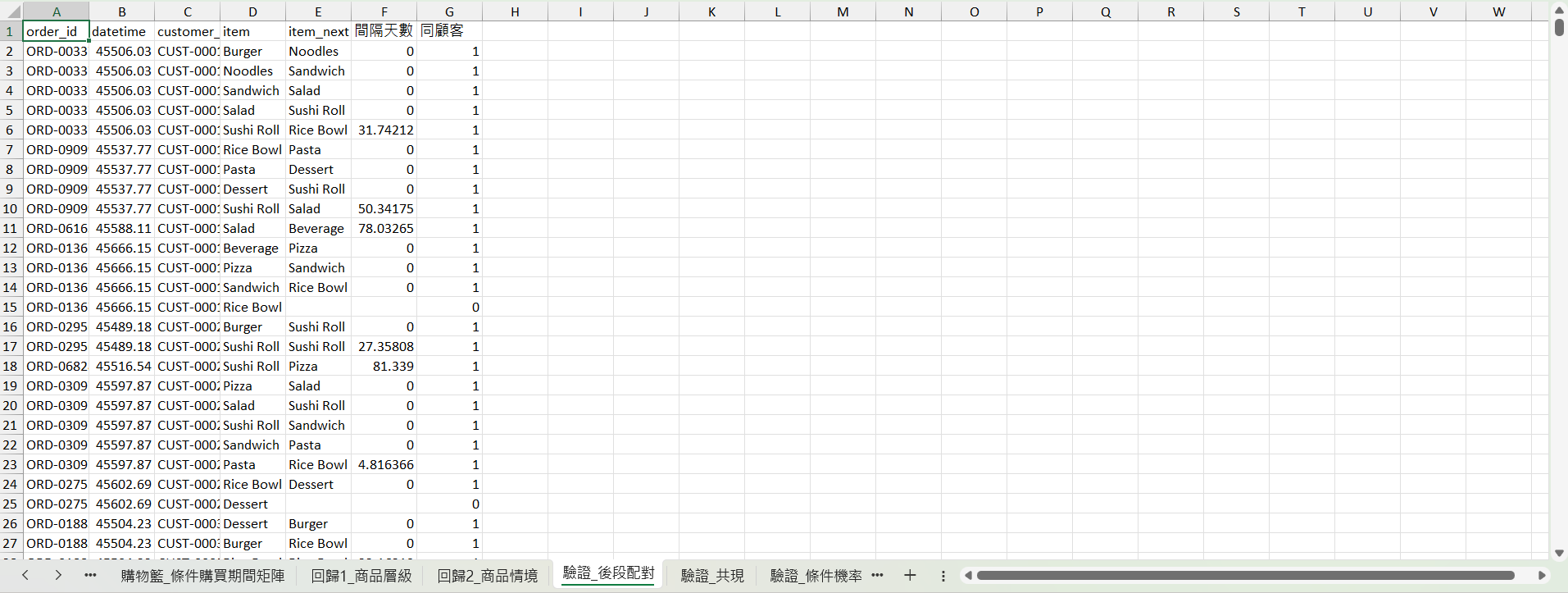
相關係數矩陣 → 算後段同單共現的相關係數矩陣,與前段做 元素相關(Pearson on off-diagonal) 或 Frobenius 距離
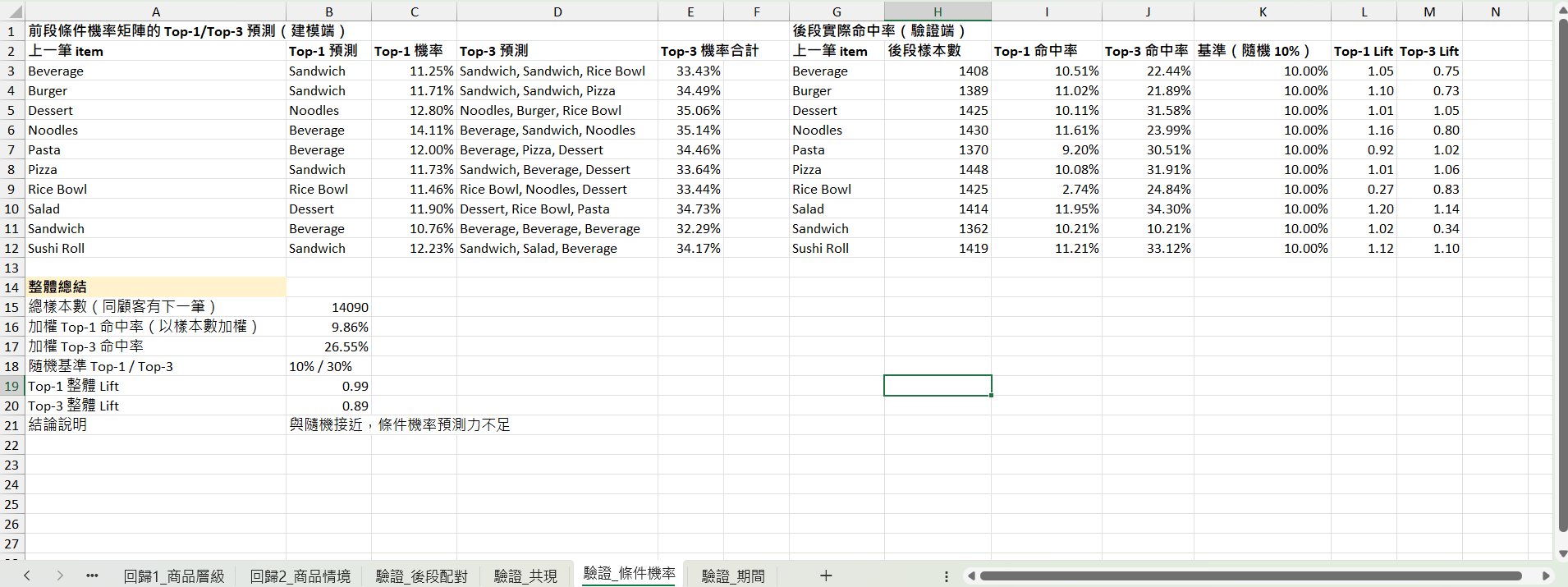
條件機率矩陣 → 對每位顧客「上一筆=A」的所有後續,預測機率最高的 B;計算:
Top-1 命中率、Top-3 命中率
Brier score 或 Log-loss(用前段機率當預測分布,後段實際 one-hot 當真實值)
對照基準:用後段商品邊際分布當「無腦預測」,看條件機率有沒有比基準好
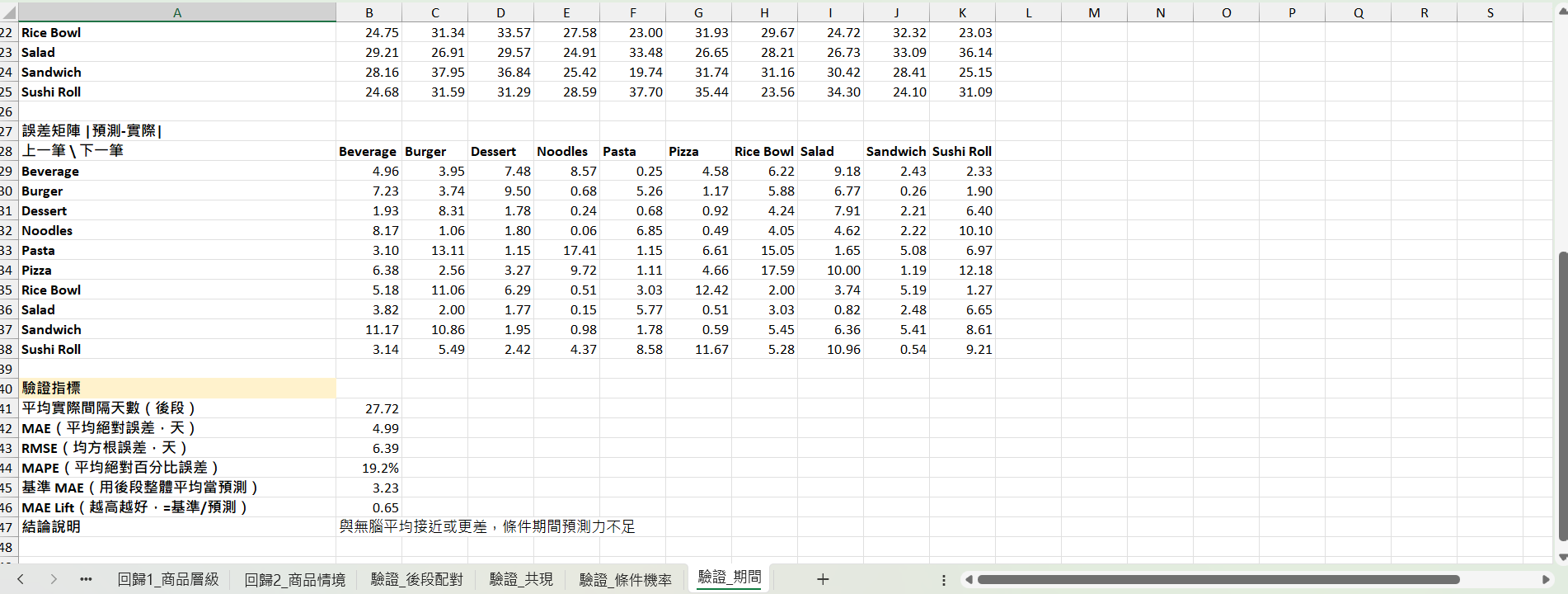
條件購買期間矩陣 → 對後段每組 (A→B) 配對,比對實際間隔天數:
MAE、RMSE、MAPE
對照基準:用整體平均間隔(≈30 天)當「無腦預測」
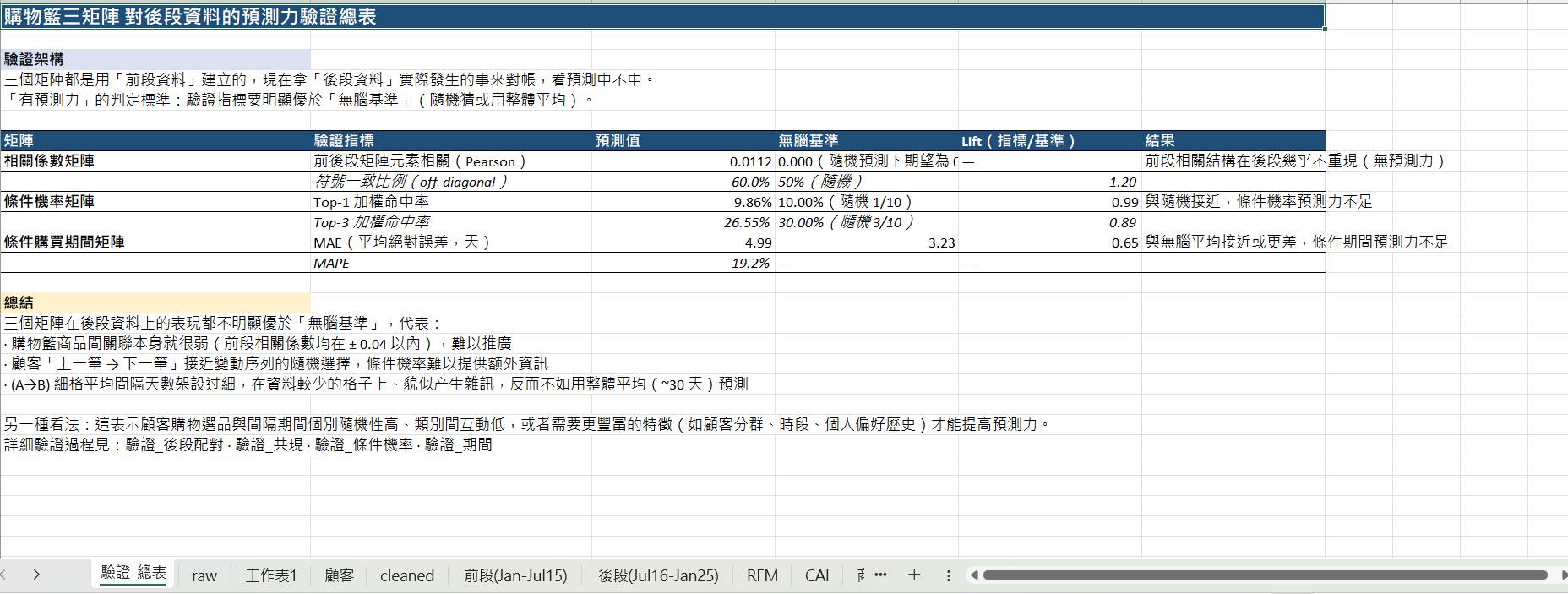
Step 3:總表 一個摘要表把三個指標、基準、是否優於基準(lift)放在一起,就能直接回答「有沒有用」。
驗證結果
三個矩陣對後段資料都沒有顯著預測力:
為什麼會這樣
前段 購物籃_相關係數矩陣 的所有相關係數都在 ±0.04 內,本來就是噪音水準的關聯,當然推不到後段。
顧客的「上一筆 → 下一筆」幾乎是獨立隨機選擇,條件機率沒帶來資訊。
(A→B) 細格平均間隔過度切割資料(每格樣本數小),反而學到雜訊;用整體 ~30 天平均反而更穩。
同次交易
然後我也要做做看同次購買的購物籃分析。計算三個東西即可:
支援度:同時購買A和B訂單數 / 總購買訂單數。A商品和B商品同時被購買的機率,支援度越大,商品間關聯性越強。
置信度:同時購買A和B訂單數 / 購買A的訂單數。因為購買了A所以購買了B的機率。
提升度:支援度 / ( (購買A次數/總購買訂單數)*(購買B次數/總購買訂單數) )。先購買A對購買B的提升作用,用來判斷商品組合方式是否具有實際價值,大於1說明該組合方式有效,小於1則說明無效。
叫 Claude 幫我做。
支援度:同時購買A和B訂單數 / 總購買訂單數。A商品和B商品同時被購買的機率,支援度越大,商品間關聯性越強。
置信度:同時購買A和B訂單數 / 購買A的訂單數。因為購買了A所以購買了B的機率。
提升度:支援度 / ( (購買A次數/總購買訂單數)*(購買B次數/總購買訂單數) )。先購買A對購買B的提升作用,用來判斷商品組合方式是否具有實際價值,大於1說明該組合方式有效,小於1則說明無效。
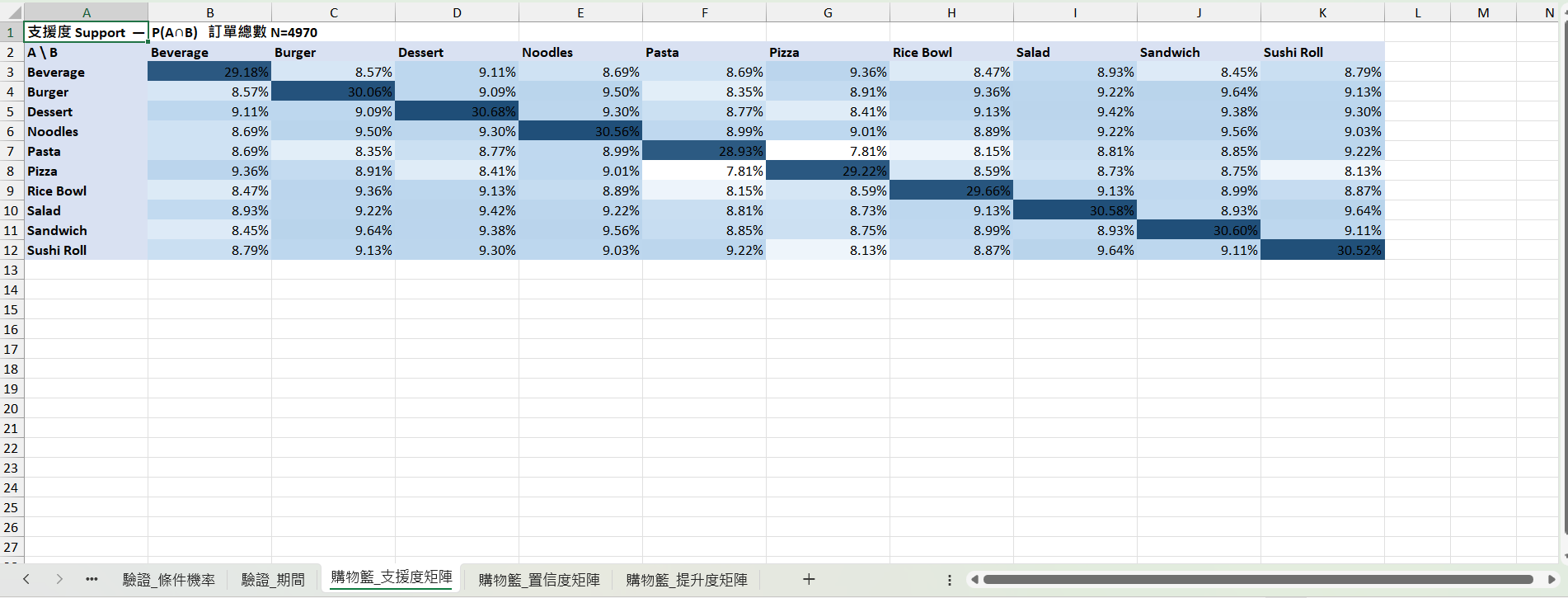
利用 前段_展開_購物籃 的資料 幫我做出 支援度矩陣 置信度矩陣 提升度矩陣完成。三張矩陣已建好(列=A、欄=B,N=4970 訂單):
購物籃_支援度矩陣:%顯示,對角為 P(A) 該商品自身出現率
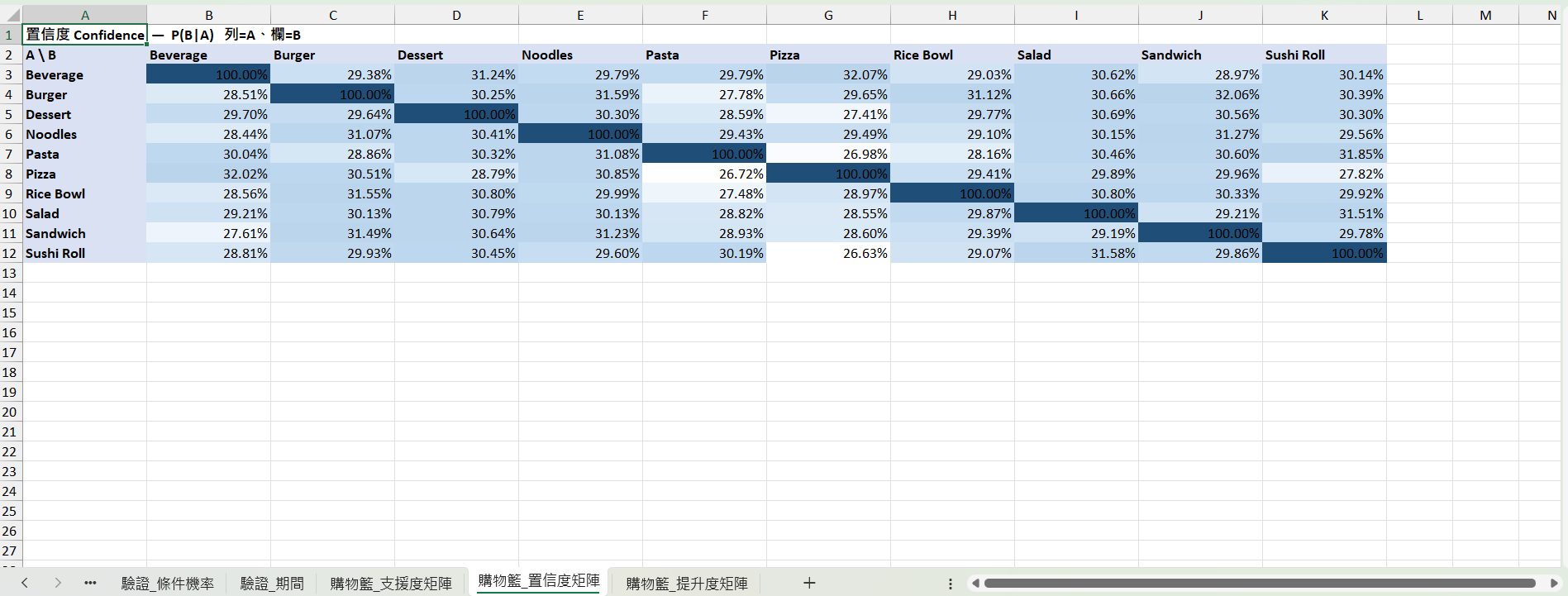
購物籃_置信度矩陣:P(B|A),對角設 1
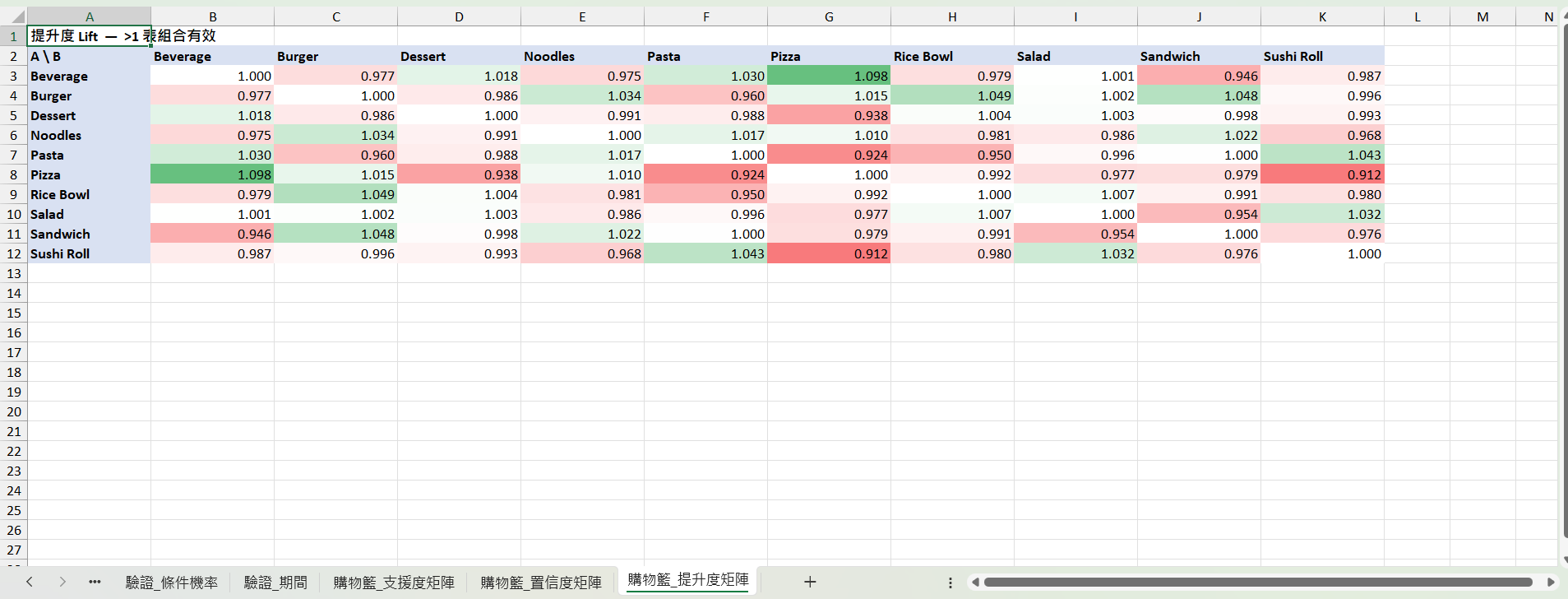
購物籃_提升度矩陣:以 1 為中點紅↔綠色階,>1 才有提升
提示:這份資料 10 種商品的支援度都落在 8–10%、提升度多在 0.95–1.05 之間,組合效應整體偏弱;可挑色階偏綠的格子(例如 Sandwich↔Burger、Salad↔Sushi Roll)作為主推搭售。
支援度矩陣

置信度矩陣

提升度矩陣
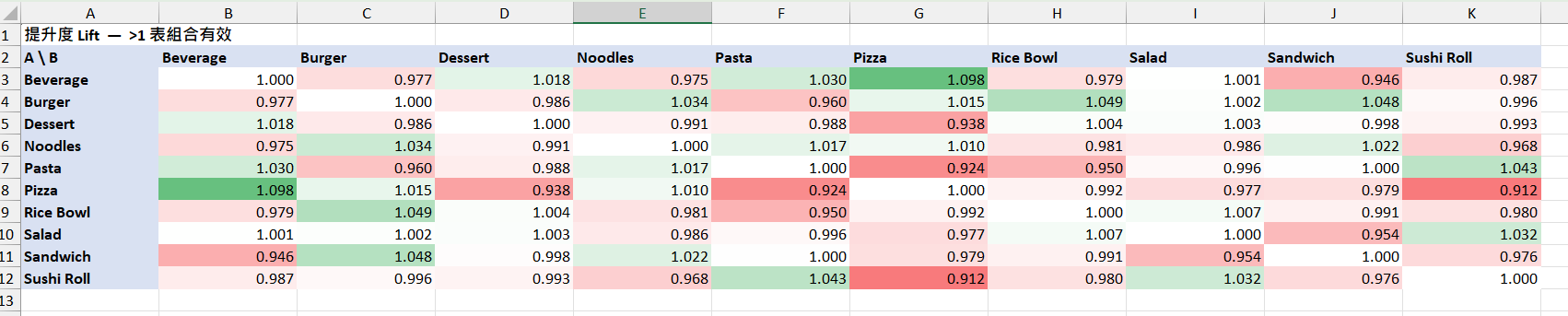
驗證
用 後段_展開_購物籃 的資料驗證這三個矩陣是否有預測力結論:這三個矩陣基本沒有預測力。
Top-10 lift 命中率 40%(隨機水準就是 ~50%,因為後段 90 對中本來就有約一半 >1)
方向一致性 60%(接近擲銅板的 50%)
白話: 前段挑出的「強組合」到後段就洗牌了。10 樣商品的單品出現率都在 28–31% 之間,搭配率也都壓在 8–10%,整個資料看起來像各品項彼此獨立隨機被點選——換句話說,這份資料中 顧客點 A 不會讓他更想點 B。把前段任何一格的 lift 拿來預測後段的同一格,效果跟亂猜差不多。
如果這是課堂作業要展示 Apriori 的限制,這個結果本身就是有意義的發現;如果是要找真實的搭售規則,這份資料可能是隨機生成的、或要用更大的訂單顆粒度(時段、客群)切後再算。
看來購物籃分析在這份資料上行不通。
結論
兩種購物籃分析做完,結果出乎意料地一致:都沒有預測力。
跨交易的三個矩陣(相關、條件機率、條件購買期間)對後段的命中率比隨機猜還略差;同交易的三個指標(支援度、置信度、提升度)前後段的相關係數都接近 0、Top-10 lift 命中 40%(隨機水準 50%)。換句話說,從前段挑出來「看起來最有關聯」的商品組合,到後段全部洗牌。
為什麼兩種都失效
關鍵不在方法,而在資料本身。10 樣商品的單品出現率都壓在 28–31%、同單搭配率都在 8–10%、提升度幾乎都落在 0.95–1.05。這個分布長得就像「每個商品被獨立隨機點選」——在獨立分布上做關聯分析,無論用哪個方法都只會學到雜訊,當然推不到後段。這份 demo 資料八成是隨機生成的。
哪種方法比較適合
雖然兩種在這份資料上都不適用,但理論上各有適合的場景:
這份資料是餐飲訂單,理論上應該比較吃同交易視角,但實證上連同交易也看不到規律,再次印證資料的獨立性。
方法論的收穫
這次最大的收穫其實不是方法本身,而是驗證設計:
沒做後段驗證之前,前段的相關係數 0.04、條件機率 9% 看起來都還像那麼一回事;做完驗證才知道是噪音水準。
基準對照不能省——條件購買期間 MAE 4.99 天聽起來合理,對比「全體平均 3.23 天」這個無腦預測才看出是 Lift 0.65 的負貢獻。
「沒規律」本身就是有效的發現。把不合適的方法硬套上去做出漂亮數字,反而會誤導後續搭售決策;嚴謹地確認「資料沒規律」,這個結論對下一步行動(不該用購物籃分析做這份資料的推薦)有實質意義。