
最近深陷期末地獄的泥淖中,有堂課的期末報告是要自己找資料、用 Python 做分析並畫成圖表。過程中我真的體會到 Pandas 的難用。我自己做的 Go 語言資料分析函式庫—Insyra 好用多了。
雜亂無章的輸出
Pandas DataFrame 的輸出根本是悲劇,大家如果不理解,我這邊丟個圖。
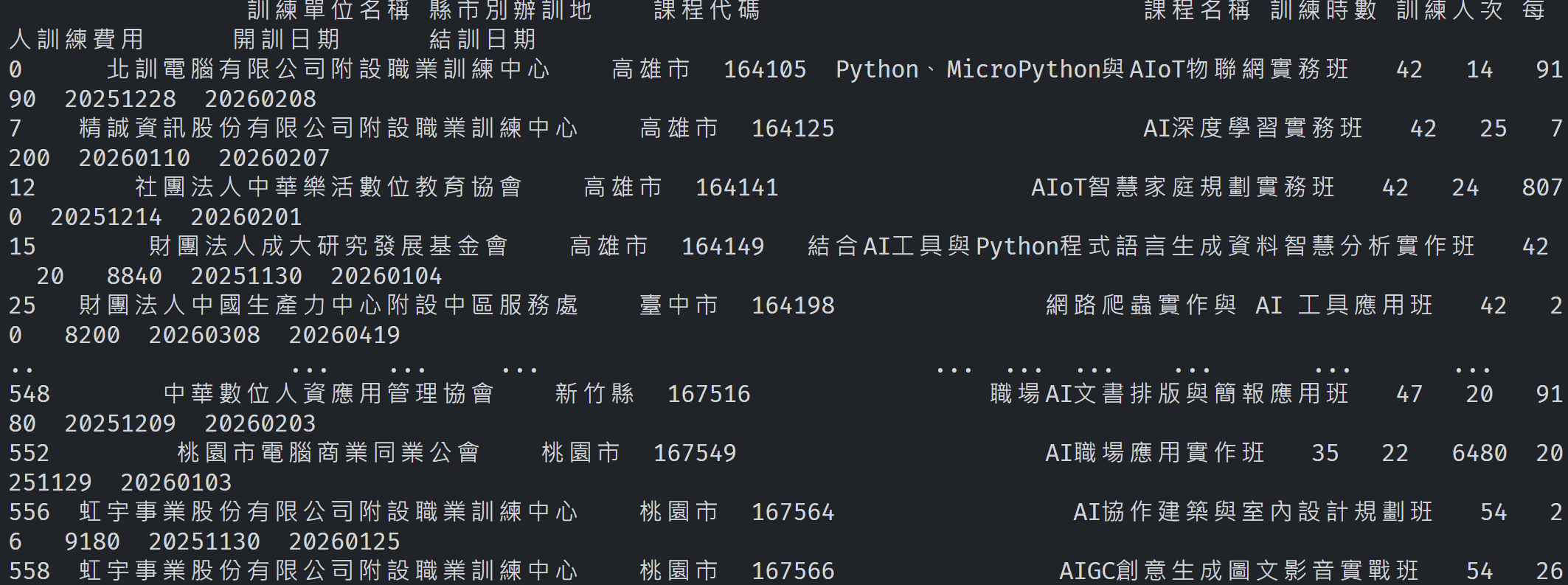
我就問這到底怎麼看?表頭跟資料內容都沒對齊,資料甚至都擠在一起。與其 print 出來看這鬼東西,我還不如直接打開 Excel 比較快!
再來看看 Insyra 是怎麼做的:
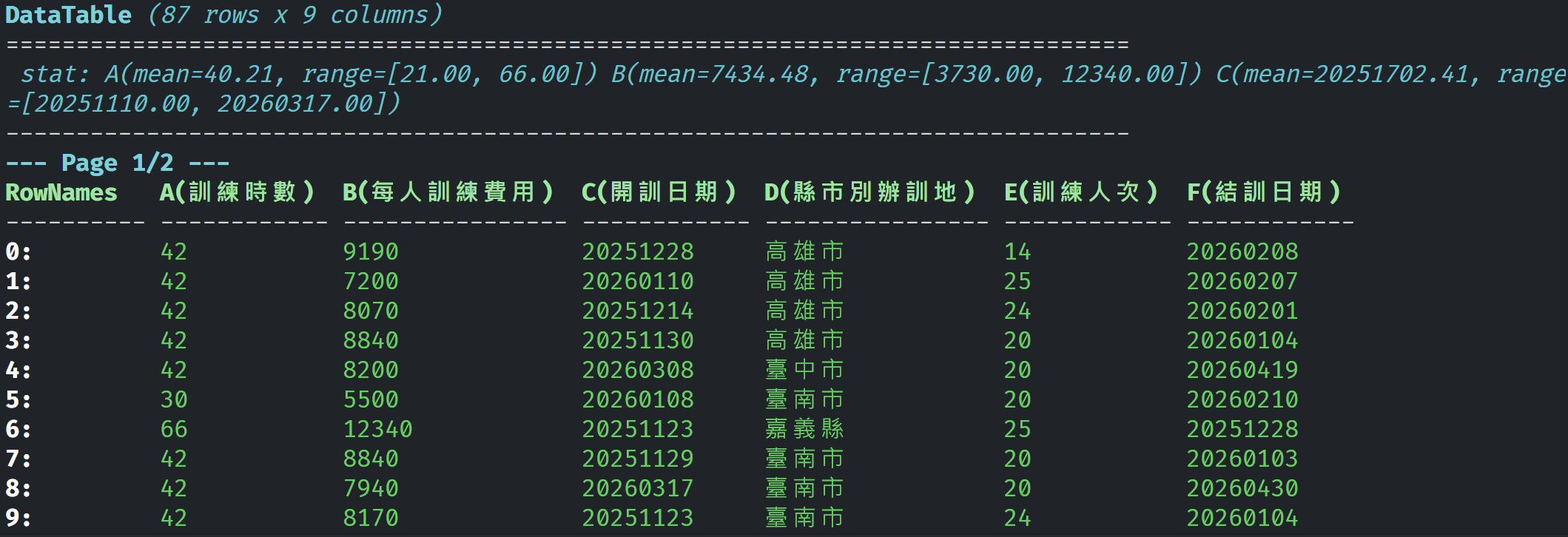
是不是清楚很多?放不下就放下一頁嘛,很困難嗎???
Insyra 甚至還貼心的附上簡易的快速統計,讓你的資料一目了然。
本來不就該是這樣嗎?如果一個資料分析工具在使用時,還要時不時打開 Excel 看資料,那我為什麼不直接用 Excel 分析就好啊?
不明確的資料複製規則
當 Pandas 在傳遞 DataFrame 或 Series 資料結構時,到底會不會複製其中的值呢?答案是:看它心情🤡!
下面我們用兩種寫法做同樣的事情(把 A 欄大於 10 的列,B 欄分別改成 0 或 9),猜猜看哪一個能成功修改 DataFrame 中的資料。
假設我們有同樣一組資料:
import pandas as pd
df = pd.DataFrame({
"A": [5, 15, 25],
"B": [100, 200, 300]
})寫法A
# 先取欄位,再用 loc
df["B"].loc[df["A"] > 10] = 0
print(df)寫法B
# 先用條件篩選,再取欄位
df[df["A"] > 10]["B"] = 9
print(df)好了,問題來了。我們依序執行寫法 A 和 B 之後,現在 df 裡的 B 欄到底會是 [100, 200, 300] 、[100, 0, 0] 還是 [100, 9, 9] 呢🤔?
公布解答:
A B
0 5 100
1 15 0
2 25 0
<ipython-input-3-93c7d5817c42>:3: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame.
Try using .loc[row_indexer,col_indexer] = value instead
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
df[df["A"] > 10]["B"] = 9答案是 [100, 0, 0] 。也就表示,寫法 A 是直接修改原 DataFrame 的值,寫法 B 則是修改複製後的 DataFrame。
在這個案例中,df["B"].loc[df["A"] > 10] 回傳的是原 DataFrame 裡的 Series,df[df["A"] > 10]["B"] 則是回傳複製的。我問了 GPT,他說後者甚至不保證在所有情況下都是複製的,而是無法確定。
這實在太瘋了!
作為一個 47.3K 顆星的專案,竟然連這麼基礎的資料操作邏輯都做不好。更可怕的是,這樣的函式庫已經成為 Python 資料分析的核心基礎。
反觀 Insyra 在每次取得資料的操作都是採用值回傳,如果要改變原內容再手動存回去,語法上非常明確。
上面案例的等效 Go 程式碼如下:
package main
import (
"github.com/HazelnutParadise/insyra"
)
func main() {
dt := insyra.NewDataTable(
insyra.NewDataList(5, 15, 25),
insyra.NewDataList(100, 200, 300),
)
dt = dt.Map(func(rowIndex int, colIndex string, element any) any {
if (colIndex == "B") && (dt.GetElement(rowIndex, "A").(int) > 10) {
return 0
}
return element
})
dt.Show()
}輸出:
DataTable (3 rows x 2 columns)
================================================================================
stat: A(mean=15.00, range=[5.00, 25.00]) B(mean=33.33, range=[0.00, 100.00])
--------------------------------------------------------------------------------
RowNames A B
---------- --- ----
0: 5 100
1: 15 0
2: 25 0由於 Go 語言的語法限制,使用上比 Pandas 複雜了點,但至少行為是可預測的。Insyra 的使用方式也會在未來持續改進,會越來越容易使用。
如果真的還是覺得太難,可以試試 CCL(Column Colculation Language),這是 Insyra 中一個類似 Excel 公式的語法。
package main
import (
"github.com/HazelnutParadise/insyra"
)
func main() {
dt := insyra.NewDataTable(
insyra.NewDataList(5, 15, 25),
insyra.NewDataList(100, 200, 300),
)
dt.ExecuteCCL("B=IF(A>10, 0, B)")
dt.Show()
}輸出一模一樣:
DataTable (3 rows x 2 columns)
================================================================================
stat: A(mean=15.00, range=[5.00, 25.00]) B(mean=33.33, range=[0.00, 100.00])
--------------------------------------------------------------------------------
RowNames A B
---------- --- ----
0: 5 100
1: 15 0
2: 25 0 Insyra 資料分析函式庫
GitHub Repo:https://github.com/HazelnutParadise/insyra
官方網站:https://insyra.hazelnut-paradise.com
緣起
我認識了 Go 語言之後,認為它語法簡單與高並發的特性,非常適合用於資料的計算。目前主流的資料分析工具大概就是 SPSS、R 語言、Python 等,SPSS 如果資料量太大會沒辦法跑,而程式語言如 R、Python 等,又都是直譯型的語言,記憶體消耗大、跑得又慢,也不太擅長平行運算。
所以我覺得 Go 語言或許能在資料分析領域有很大的潛力,然而它卻十分缺乏與資料分析相關的函式庫,於是我決定自己做一個。
2024/8/29,在 Side Project Taiwan 社群成員的鼓勵下,我開了這個 repo,其後的開發也非常感謝所有貢獻者與學校老師的協助。
特性
Insyra 有幾個設計哲學,或者與其說是哲學,不如說是取捨:
資料分析瑞士刀
Insyra 最主要的使命就是成為 Go 語言資料分析的萬能工具包,我們不像很多函式庫偏好追求零第三方依賴,反而用了很多,並且把各種功能包裝成統一且更易於使用的介面。幫助使用者省下自己去尋找套件包的時間和心力。
盡量減少複雜
Go 語言與 Python 最大的不同是:Go 是靜態型別的語言。這在資料處理時就會遇到一個問題,我們往往沒辦法把不同資料型態的東西塞在一起操作。
Insyra 的資料結構解決了這個問題,我們利用空 interface 切片作為底層結構的主要部分,來支援任何型態的資料。同時,我們把麻煩的爛事(例如斷言等)盡量隱藏在函式或結構體方法的內部邏輯裡,目的就是希望讓使用者更容易上手。
不直接回傳錯誤
這點就更像是取捨了。為了讓方法可以鏈式呼叫,我們大部分的方法都不直接回傳錯誤,而是採用 log 輸出 + 回傳 nil 的方式。但這樣會有錯誤處理不易的缺點,為此我們的補救方法是額外提供一個 錯誤緩衝區 來儲存錯誤,並且使用者可以設置錯誤處理函式,可自動在錯誤時執行。
基本結構
Insyra 目前有兩種資料結構,分別是一維的 DataList 和二維的 DataTable。
DataList
我們可以用以下方式建立 DataList:
dl := insyra.NewDataList(1, 2, 3, 4, 5)或是使用語法糖:
dl := isr.DL.From(1, 2, 3, 4, 5) // 需要 import "github.com/HazelnutParadise/insyra/isr"DataTable
以下方式建立 DataTable:
col1 := insyra.NewDataList(1, 2, 3, 4, 5)
col2 := insyra.NewDataList(6, 7, 8, 9, 10)
col3 := insyra.NewDataList(11, 12, 13, 14, 15)
dt := insyra.NewDataTable(col1, col2, col3)語法糖:
col1 := isr.DL.From(1, 2, 3, 4, 5)
col2 := isr.DL.From(6, 7, 8, 9, 10)
col3 := isr.DL.From(11, 12, 13, 14, 15)
dt := isr.DT.From(isr.DLs{col1, col2, col3})DataList 和 DataTable 的使用方式可以參考文件:
子套件包
Insyra 除了提供資料分析的基本結構,也內建很多子套件包,涵蓋各種功能。每個套件包的用法都可以在文件裡找到。
這些文件都是針對 AI 優化過的,可以直接丟給 LLM 問,也可以用 Context7 的 MCP 和 Chatbot:
大家快去嘗試看看吧~