
這是整個專題最核心的部分。小小商家一點靈利用 RFM 與 CAI 模型,幫助商家將顧客分群,方便進行顧客管理與個人化行銷。這部份的計算,是使用我自己開發的資料分析函式庫——Insyra 來實作。
關於 Insyra 函式庫的更多資訊,可以參考我之前寫的這篇:別再 Pandas 啦🙄,用 Insyra 來做資料分析吧!
RFM
RFM 顧名思義就是 R 跟 F 跟 M,分別代表 Recency、Frequency 與 Monetary。
R (Recency):最近一次消費
意義:顧客最近一次購買距離現在有多久。
代表:活躍度。越近代表活躍度越高。
F (Frequency):消費頻率
意義:在一定期間內,顧客的購買次數。
代表:忠誠度。次數越多,表示越忠誠。
M (Monetary):消費金額
意義:在一定期間內,顧客的總消費金額。
代表:貢獻度/價值。金額越高,貢獻越大。
這三項指標的單位都不一樣,要把他們綜合起來衡量顧客價值,我們可以依照 RFM 為每一位顧客評分,將顧客分群,評分的方法很多種:
均分法
Insyra 的 mkt 套件目前採用的算法。
將顧客分為 N 群。分別將 R 由小排到大、F 和 M 由大排到小,每個指標各自分成幾個等級(例如 1-5 分),分數越高代表該指標表現越好。
例如分為五群時,前 20%(第 80 百分位數) 的顧客獲得 5 分、次 20% 獲得 4 分,以此類推。
常見的使用方式是將分數加總,比較顧客價值高低。分數越高代表價值越高。
我們也可以把三個指標的分數放在一起(如 111、323),當作三維空間中的座標,來將顧客依價值分群。針對不同群體的客戶提供更有針對性的服務和行銷訊息,提高客戶的回購率和忠誠度。
優點
計算方式簡單,不用複雜統計。
缺點
切越多份,每一群內的顧客異質性越低,但人數越少,樣本代表性越低。要切成幾等分,可能需要深入研究。
Bob Stone 給分法
這是一個比較複雜的給分方式,針對 R、F、M 每個指標的計分方式都不一樣。
Bob Stone 給分機制最初是為銀行信用卡業務設計,因此最重視刷卡頻率,最不重視金額高低。
CAI
CAI 的全稱是 Customer Activity Index,顧客活躍性指標,聽說是由北商校長任立中發明。
它是一個根據購買期間的算術平均數(MLE)和加權平均數(WMLE)計算的顧客價值指標,解決 RFM 沒考慮到顧客購買行為變化趨勢的限制。
CAI = (MLE - WMLE) / MLE * 100%CAI < 0:顧客每次交易的時間間隔越來越長,購買行為逐漸沉寂。
CAI = 0:顧客每次交易的時間間隔都差不多,購買行為穩定。
CAI > 0:顧客每次交易的時間間隔越來越短,購買行為越來越活躍。
MLE 的計算
MLE 好像是什麼「最大概似估計值(Maximum Likelihood Estimator)」的縮寫,但我看不懂那是啥,反正他推導出來就是購買期間的算術平均數。
MLE(購買期間的算術平均數)的計算非常簡單,是將每次交易間隔的時間加總,除以間隔數。
例如顧客 A 共進行 4 次交易(3 個間隔),第一次和第二次間隔 2 天、第二次和第三次間隔 10 天、第三次和第四次間隔 18 天,則:
MLE = (2 + 10 + 18) / 3 = 10顧客 A 的 MLE 為 10。
WMLE 的計算
WMLE 是將每次間隔的時間依據發生時間遠近加權。第一個間隔權重為 1,第二個間隔權重為 2,第三個間隔權重為 3,以此類推。
以顧客 A 的例子來說:
WMLE = (2 * (1 / (1 + 2 + 3))) + (10 * (2 / (1 + 2 + 3))) + (18 * (3 / (1 + 2 + 3)))
= 2 * 1/6 + 10 * 2/6 + 18 * 3/6
= 2/6 + 20/6 + 54/6
= 76/6
≈ 12.67顧客 A 的 WMLE 約等於 12.67。
Insyra 的 mkt 套件包實作
我把 RFM 和 CAI 的計算邏輯寫成函數放在 Insyra 裡,整理成 mkt 行銷分析套件包。後端 Go 程式再引入 Insyra 來使用。這麼做有幾個好處:
在實作畢業專題的同時,也擴充 Insyra 資料分析函式庫的功能。
將行銷分析的計算方式做成可重用的函數,以後任何人只要引入 Insyra,就可以很方便地在別的程式裡呼叫使用。
當我完成畢業專題時,不但達到畢業門檻,也為社會做出貢獻,達到一舉數得的效果。
RFM 函數
接下來分享 Insyra 內部如何實作 RFM 分析的邏輯。
函數簽名
func RFM(dt insyra.IDataTable, rfmConfig RFMConfig) insyra.IDataTable計算 RFM 的函數就叫做 RFM,非常直覺。
這個函數接收兩個參數:
dt:包含交易紀錄的資料表(DataTable)。rfmConfig:RFM 分析的設定。
算完之後會回傳一個新的資料表,包含每個顧客的 RFM 分數。
設定結構(RFMConfig)
type RFMConfig struct {
CustomerIDColIndex string // 顧客ID欄位索引(A, B, C, ...)
CustomerIDColName string // 顧客ID欄位名稱
TradingDayColIndex string // 交易日期欄位索引
TradingDayColName string // 交易日期欄位名稱
AmountColIndex string // 金額欄位索引
AmountColName string // 金額欄位名稱
NumGroups uint // 要分成幾群
DateFormat string // 日期格式(例如 "YYYY-MM-DD")
TimeScale TimeScale // 時間尺度(hourly, daily, weekly, monthly, yearly)
}這個設定結構讓函數更有彈性,可以適應不同格式的資料表。欄位可以用索引(A, B, C)或名稱來指定,如果兩者都提供則優先使用索引。
計算邏輯拆解
RFM 函數的計算可以分成幾個步驟:
步驟一:資料整理
首先要從交易紀錄中,整理出每個顧客的關鍵資訊。
遍歷交易紀錄,蒐集每個顧客的資料
我們需要準備幾個 map 來儲存每個顧客的資料:
customerLastTradingDayMap := make(map[string]int64) // 記錄每個顧客的最後交易日
customerTradingFrequencyMap := make(map[string]uint) // 記錄每個顧客的交易頻率
customerTotalAmountMap := make(map[string]float64) // 記錄每個顧客的總消費金額
customerTradingPeriodsMap := make(map[string]map[string]bool) // 記錄每個顧客在哪些時間段有交易
dt.AtomicDo(func(dt *insyra.DataTable) {
numRows, _ := dt.Size()
for i := range numRows {
// 從資料表中取出這筆交易的資料
dateValue := dt.GetElement(i, tradingDayColIndex)
lastTradingDayStr := utils.ConvertToDateString(dateValue, goDateFormat)
customerID := conv.ToString(dt.GetElement(i, customerIDColIndex))
amount := conv.ParseF64(dt.GetElement(i, amountColIndex))
// 跳過無效的資料
if lastTradingDayStr == "" || customerID == "" {
continue
}
// 解析日期字串,並轉換為 UTC 以避免時區問題
lastTradingDay, err := time.Parse(goDateFormat, lastTradingDayStr)
if err != nil {
continue
}
lastTradingDayUTC := lastTradingDay.UTC()
lastTradingDayUnix := lastTradingDayUTC.Unix()
// 根據 TimeScale 格式化交易時間,用於計算不重複的交易頻率
formattedPeriod := formatTradingPeriod(lastTradingDayUTC, timeScale)
// 初始化該客戶的交易時間記錄
if _, exists := customerTradingPeriodsMap[customerID]; !exists {
customerTradingPeriodsMap[customerID] = make(map[string]bool)
}
// 如果該交易時間段尚未記錄,才累加交易頻率(F)
if !customerTradingPeriodsMap[customerID][formattedPeriod] {
customerTradingPeriodsMap[customerID][formattedPeriod] = true
if _, exists := customerTradingFrequencyMap[customerID]; !exists {
customerTradingFrequencyMap[customerID] = 0
}
customerTradingFrequencyMap[customerID]++
}
// 計算最後交易日(R)
if existingLastTradingDay, exists := customerLastTradingDayMap[customerID]; !exists || lastTradingDayUnix > existingLastTradingDay {
customerLastTradingDayMap[customerID] = lastTradingDayUnix
}
// 計算總交易金額(M)
if _, exists := customerTotalAmountMap[customerID]; !exists {
customerTotalAmountMap[customerID] = 0.0
}
customerTotalAmountMap[customerID] += amount
}
})這段程式碼逐列讀取交易紀錄,對每一筆交易取出顧客 ID、交易日期和金額,然後分別計算用於 R 的最後交易日,以及 F、M 兩個指標。
計算 R(Recency)
對每個顧客,取出他最後一次交易的日期,然後計算從他最後一次交易到現在過了多久。這裡要注意的是,時間差異的計算要根據使用者設定的時間尺度(例如是用「天」還是「小時」來計算)。
// 計算當前時間
now := time.Now().UTC()
// 對每個顧客計算距離最後交易日的時間差
for customerID, lastTradingDayUnix := range customerLastTradingDayMap {
lastTradingDay := time.Unix(lastTradingDayUnix, 0).UTC()
rValue := calculateTimeDifference(now, lastTradingDay, timeScale)
customerRMap[customerID] = rValue
}計算 F(Frequency)
計算每個顧客在分析期間內的交易次數。如果時間尺度設定為「天」,那同一天的多筆交易只能算一次;如果設定為「小時」,那同一小時的多筆交易算一次。
// 根據時間尺度格式化交易時間
formattedPeriod := formatTradingPeriod(lastTradingDayUTC, timeScale)
// 如果該時間段尚未記錄,才累加交易頻率
if !customerTradingPeriodsMap[customerID][formattedPeriod] {
customerTradingPeriodsMap[customerID][formattedPeriod] = true
customerTradingFrequencyMap[customerID]++
}計算 M(Monetary)
把每個顧客所有交易的金額加總起來。
// 累加每個顧客的總交易金額
customerTotalAmountMap[customerID] += amount步驟二:計算分組門檻
當我們有了每個顧客的 R、F、M 數值後,要把他們分成幾個等級。我採用的是均分法:把所有顧客的數值排序,然後用百分位數來切分。
例如要分成 5 群(1-5 分),就計算第 20、40、60、80 百分位數作為門檻。
// 計算R分組門檻(注意:R值越小越好,所以是反向計分)
for i := 0; i < int(numGroups)-1; i++ {
percentile := float64(i+1) / float64(numGroups) * 100
rThresholds[i] = allRValues.Percentile(percentile)
}
// 計算F分組門檻(F值越大越好,所以是正向計分)
for i := 0; i < int(numGroups)-1; i++ {
percentile := float64(i+1) / float64(numGroups) * 100
fThresholds[i] = allTradingFrequencies.Percentile(percentile)
}
// 計算M分組門檻(M值越大越好,所以是正向計分)
for i := 0; i < int(numGroups)-1; i++ {
percentile := float64(i+1) / float64(numGroups) * 100
mThresholds[i] = allTotalAmounts.Percentile(percentile)
}這裡要特別注意的是:R 分數是反向計算的。為什麼?因為 R 代表「距離上次交易的天數」,天數越小代表越活躍,應該得到越高的分數。而 F 和 M 則是正向計算,數值越大分數越高。
步驟三:為每個顧客評分
有了門檻值後,就可以為每個顧客計算分數了。
// 計算分數的邏輯
func calculateScore(value float64, thresholds []float64, ascending bool) int {
score := 1
for _, threshold := range thresholds {
if ascending {
// 正向計分:值越大分數越高
if value > threshold {
score++
}
} else {
// 反向計分:值越小分數越高
if value <= threshold {
score++
}
}
}
return score
}這個函數的邏輯很簡單:從最低分(1分)開始,每超過一個門檻就加一分。ascending 參數決定是正向還是反向計分。
步驟四:輸出結果
最後把每個顧客的 R、F、M 分數和總分整理成一個新的資料表。
// 創建RFM結果表
rfmTable := insyra.NewDataTable()
// 為每個顧客計算分數
for customerID := range customerLastTradingDayMap {
rScore := calculateScore(float64(rValue), rThresholds, false)
fScore := calculateScore(float64(fValue), fThresholds, true)
mScore := calculateScore(mValue, mThresholds, true)
rfmScore := rScore + fScore + mScore
// 添加到結果表中
rowData := map[string]any{
"A": customerID,
"B": rScore,
"C": fScore,
"D": mScore,
"E": rfmScore,
}
rfmTable.AppendRowsByColIndex(rowData)
}
// 設定欄位名稱
rfmTable.SetColNameByIndex("A", "CustomerID")
rfmTable.SetColNameByIndex("B", "R_Score")
rfmTable.SetColNameByIndex("C", "F_Score")
rfmTable.SetColNameByIndex("D", "M_Score")
rfmTable.SetColNameByIndex("E", "RFM_Score")如何使用 RFM 函數
理解了計算邏輯後,來看看實際上要怎麼使用這個函數。
我們使用 Kaggle 上的超市資料作為範例:https://www.kaggle.com/datasets/eslamessam2025/supermarket
並使用我自製的資料分析整合環境——Idensyra 示範。
準備資料
交易日期必須是字串,目前版本的 RFM 函數並不支援日期物件。這在大多數使用場景下(例如從 Excel 匯入資料)已經夠用。
資料長這樣:
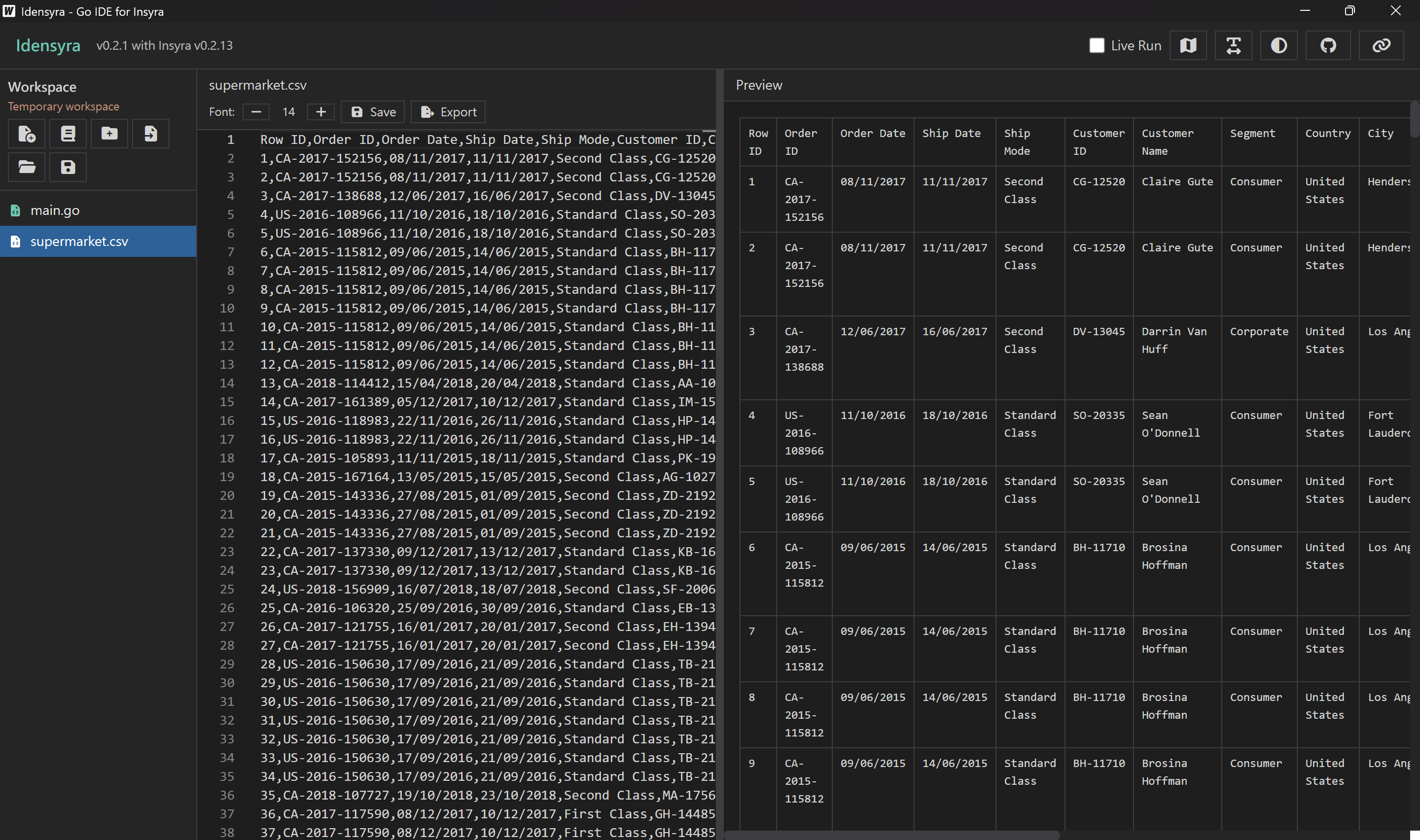
這份資料所有的列如下:
Row ID, Order ID, Order Date, Ship Date, Ship Mode, Customer ID, Customer Name, Segment, Country, City, State, Postal Code, Region, Product ID, Category, Sub-Category, Product Name, Sales設定參數
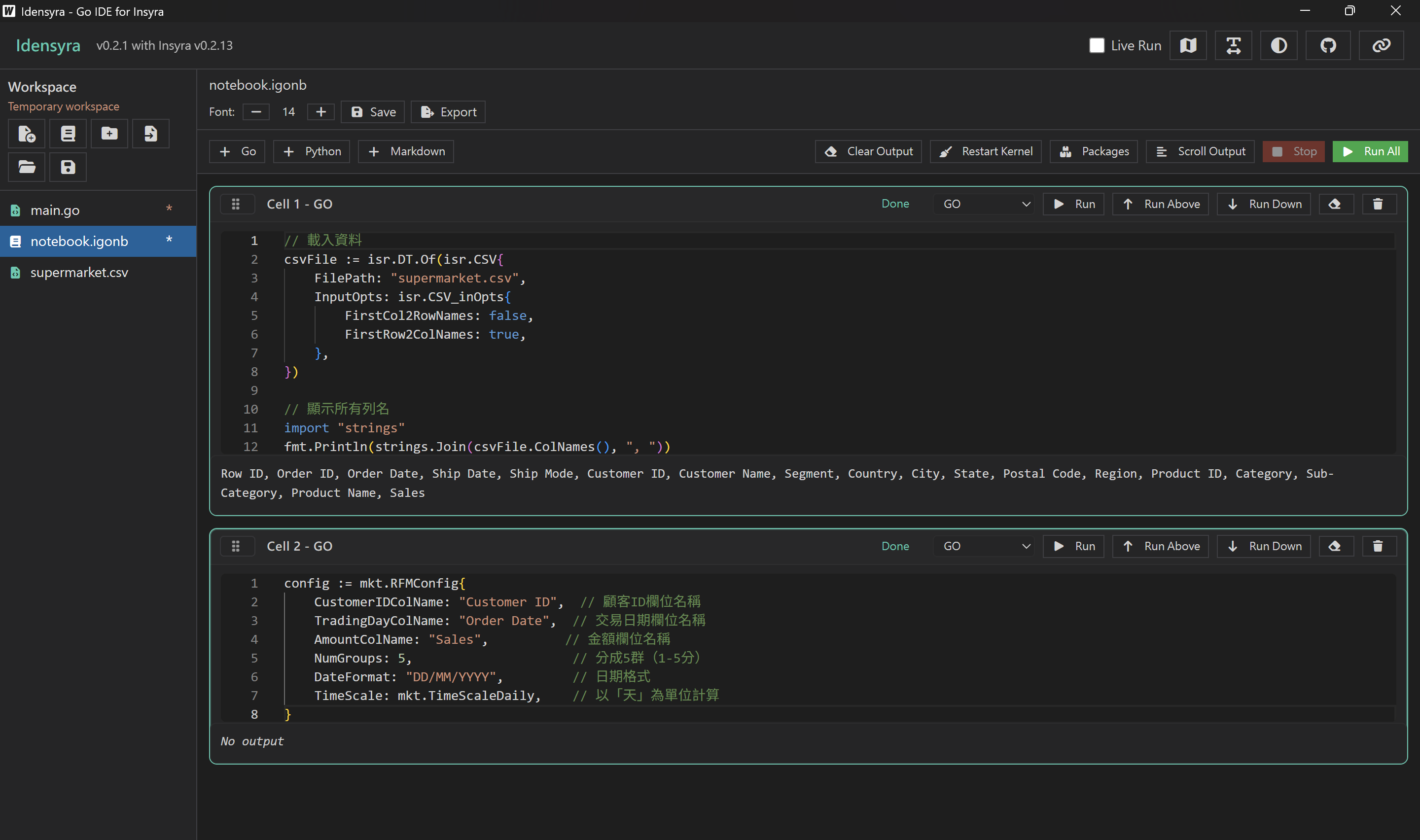
我們可以使用 Customer ID 作為顧客 ID 欄 ,Order Date 作為交易日期,Sales 作為金額欄。
日期格式則是 DD/MM/YYYY ,時間尺度設為一天。將顧客分為五組。
config := mkt.RFMConfig{
CustomerIDColName: "Customer ID", // 顧客ID欄位名稱
TradingDayColName: "Order Date", // 交易日期欄位名稱
AmountColName: "Sales", // 金額欄位名稱
NumGroups: 5, // 分成5群(1-5分)
DateFormat: "DD/MM/YYYY", // 日期格式
TimeScale: mkt.TimeScaleDaily, // 以「天」為單位計算
}
執行分析
只需要呼叫 RFM 函數就能一鍵做完分析,非常輕鬆愉快。
rfmResult := mkt.RFM(csvFile, config)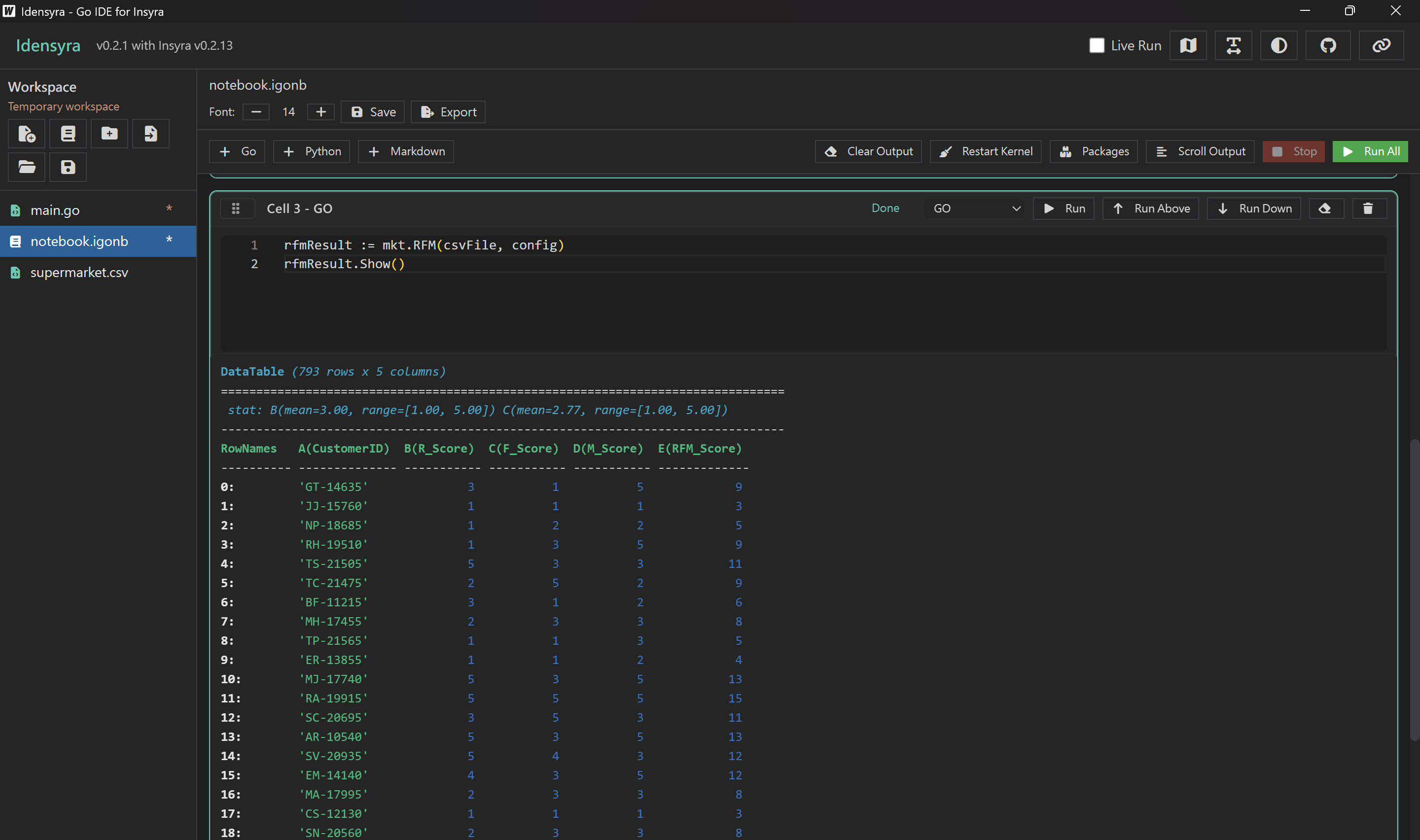
查看結果
這是我們執行後得到的資料表,包含每個顧客的 R、F、M 分數,以及分數加總:
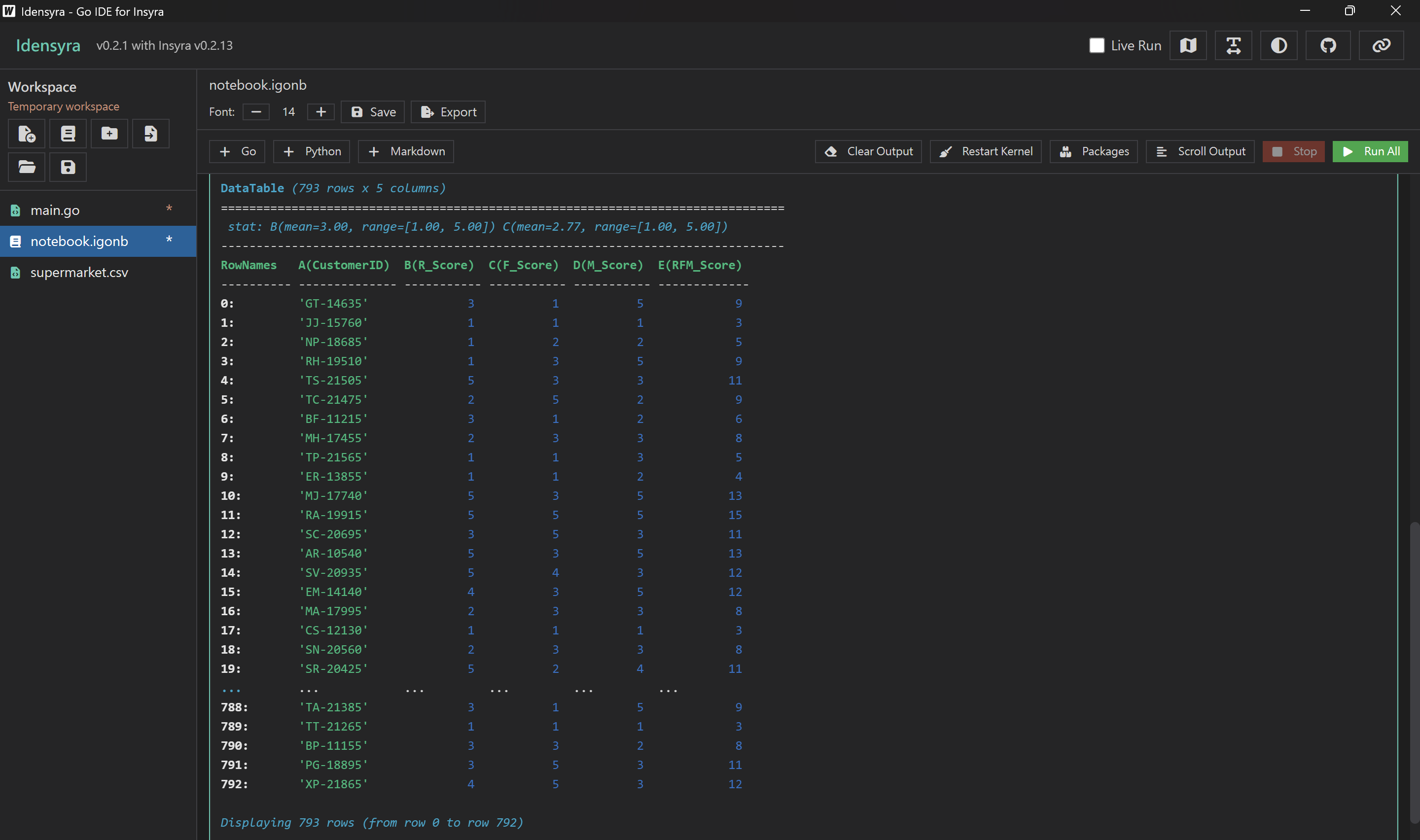
分數越高,代表顧客價值越高。你可以根據 RFM 總分或個別的 R、F、M 分數來進行顧客分群和個人化行銷。
CAI 函數
接下來分享 CAI(Customer Activity Index)的實作。
函數簽名
func CustomerActivityIndex(dt insyra.IDataTable, caiConfig CAIConfig) insyra.IDataTable這個函數也可以用別名 CAI 來呼叫,功能完全相同。之所以使用全名 CustomerActivityIndex 是考量到 CAI 指標的知名度沒有 RFM 那麼高,用全稱比較能讓使用者知道它是幹嘛的。
這個函數接收兩個參數:
dt:包含交易紀錄的資料表(DataTable)。caiConfig:CAI 分析的設定。
算完之後會回傳一個新的資料表,包含每個顧客的 MLE、WMLE 和 CAI 值。
重要限制:只有至少 4 筆交易紀錄的顧客才會被納入 CAI 計算。因為 CAI 需要至少 3 個交易間隔來判斷趨勢變化,而 3 個間隔需要 4 筆交易。
設定結構(CAIConfig)
type CAIConfig struct {
CustomerIDColIndex string // 顧客ID欄位索引(A, B, C, ...)
CustomerIDColName string // 顧客ID欄位名稱
TradingDayColIndex string // 交易日期欄位索引
TradingDayColName string // 交易日期欄位名稱
DateFormat string // 日期格式(例如 "YYYY-MM-DD")
TimeScale TimeScale // 時間尺度(hourly, daily, weekly, monthly, yearly)
}相較於 RFMConfig,CAIConfig 不需要金額欄位,因為 CAI 只關心交易時間的變化趨勢。
計算邏輯拆解
CAI 函數的計算分成以下步驟:
步驟一:蒐集每個顧客的交易時間
首先要從交易紀錄中,蒐集每個顧客的所有交易時間。
customerTransactionsTime := make(map[string][]time.Time)
dt.AtomicDo(func(dt *insyra.DataTable) {
numRows, _ := dt.Size()
for i := range numRows {
customerID := conv.ToString(dt.GetElement(i, customerIDColIndex))
tradingTimeStr := conv.ToString(dt.GetElement(i, tradingDayColIndex))
if customerID "" || tradingTimeStr "" {
continue
}
tradingTime, err := time.Parse(goDateFormat, tradingTimeStr)
if err != nil {
continue
}
customerTransactionsTime[customerID] = append(customerTransactionsTime[customerID], tradingTime)
}
})這段程式碼把每個顧客的所有交易時間都收集到一個陣列裡。
步驟二:加入最晚時間作為結束點
為了計算最後一個交易間隔,我們需要一個「結束時間點」。但是如果跟 RFM 一樣使用現在時間作為結束點,在分析過去資料時,CAI 的計算結果會被時間影響(最後一個間隔被拉大,導致分析出來的行為趨勢失真)。
因此我在這裡採用的方法是:找出所有顧客中最晚的交易時間,並將這個時間加到每個顧客的交易紀錄最後。
// 找出所有顧客中最晚的交易時間
allLastTimes := []time.Time{}
for _, times := range customerTransactionsTime {
lenTimes := len(times)
if lenTimes < 3 {
continue // 加了最晚時間前,至少需三點
}
allLastTimes = append(allLastTimes, times[lenTimes-1])
}
algorithms.ParallelSortStableFunc(allLastTimes, func(a, b time.Time) int {
return a.Compare(b)
})
latestTime := allLastTimes[len(allLastTimes)-1]
// 將最晚時間加到每個顧客的交易紀錄最後
for customerID, times := range customerTransactionsTime {
customerTransactionsTime[customerID] = append(times, latestTime)
}步驟三:計算交易間隔
有了每個顧客的交易時間序列後,就可以計算相鄰兩次交易之間的時間間隔。
for customerID, times := range customerTransactionsTime {
if len(times) < 4 {
continue // 少於4次交易無法計算CAI
}
// 先排序交易時間
insyra.SortTimes(times)
// 計算間隔
intervals := calculateIntervals(times, timeScale)
customerTransactionsIntervals[customerID] = intervals
}calculateIntervals 函數的實作:
func calculateIntervals(dateTimes []time.Time, scale TimeScale) []int64 {
if len(dateTimes) < 2 {
return nil
}
var intervals []int64
for i := 1; i < len(dateTimes); i++ {
interval := calculateTimeDifference(dateTimes[i], dateTimes[i-1], scale)
if interval < 1 {
// 同一時間尺度下的多次交易不計入間隔
continue
}
intervals = append(intervals, interval)
}
return intervals
}如果兩筆交易在同一個時間尺度內(例如同一天、同一小時),不重複計入間隔計算。
步驟四:計算 MLE(算術平均數)
MLE 就是把所有交易間隔加總後除以間隔數量。
for customerID, intervals := range customerTransactionsIntervals {
if len(intervals) == 0 {
continue
}
l := insyra.NewDataList(intervals)
mle := l.Mean()
customerMLEs[customerID] = mle
}步驟五:計算 WMLE(加權平均數)
WMLE 是將每個間隔根據發生的先後順序加權。越晚發生的間隔權重越大。
for customerID, intervals := range customerTransactionsIntervals {
if len(intervals) == 0 {
continue
}
numIntervals := len(intervals)
var weightDenominator float64
// 計算權重分母(1 + 2 + 3 + ... + n)
for i := 1; i <= numIntervals; i++ {
weightDenominator += float64(i)
}
// 計算加權平均
for i, interval := range intervals {
weight := float64(i+1) / weightDenominator
customerWMLEs[customerID] += weight * float64(interval)
}
}步驟六:計算 CAI 並輸出結果
最後依照公式 CAI = (MLE - WMLE) / MLE × 100% 計算 CAI 值。
resultDT := insyra.NewDataTable(
insyra.NewDataList().SetName("CustomerID"),
insyra.NewDataList().SetName("MLE"),
insyra.NewDataList().SetName("WMLE"),
insyra.NewDataList().SetName("CAI"),
)
for customerID, mle := range customerMLEs {
wmle := customerWMLEs[customerID]
cai := (mle - wmle) / mle * 100 // 百分比表示
resultDT.AppendRowsByColName(map[string]any{
"CustomerID": customerID,
"MLE": mle,
"WMLE": wmle,
"CAI": cai,
})
}如何使用 CAI 函數
使用方式和 RFM 類似,讓我們使用同一份資料來分析。
準備資料
同上,不再贅述。
設定參數
我們一樣把時間尺度設為天。
caiConfig := mkt.CAIConfig{
CustomerIDColName: "Customer ID",
TradingDayColName: "Order Date",
DateFormat: "DD/MM/YYYY",
TimeScale: mkt.TimeScaleDaily,
}
執行分析
馬上就把每一位顧客的 CAI 指標算出來了,等都不用等。
caiResult := mkt.CAI(csvFile, caiConfig)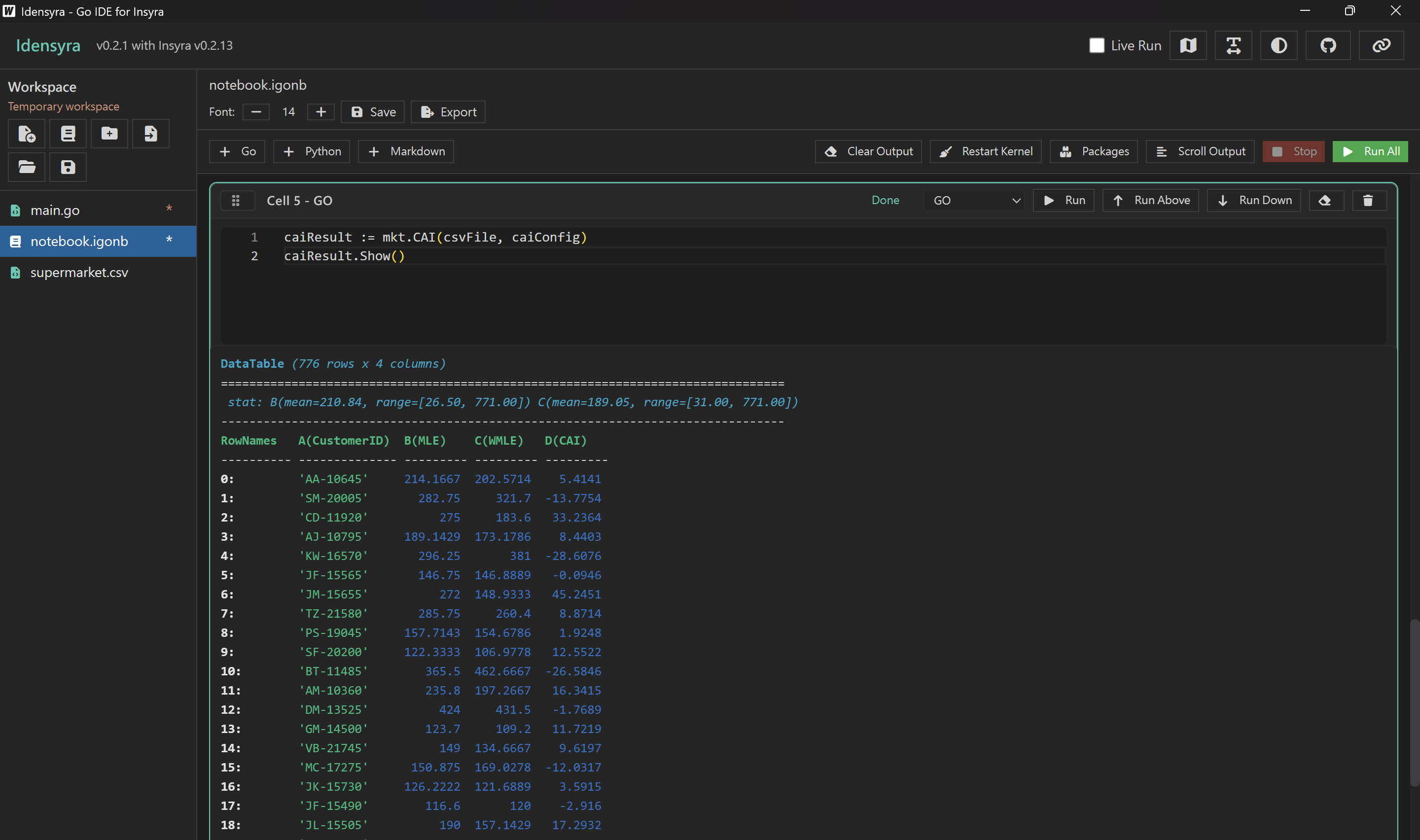
查看結果
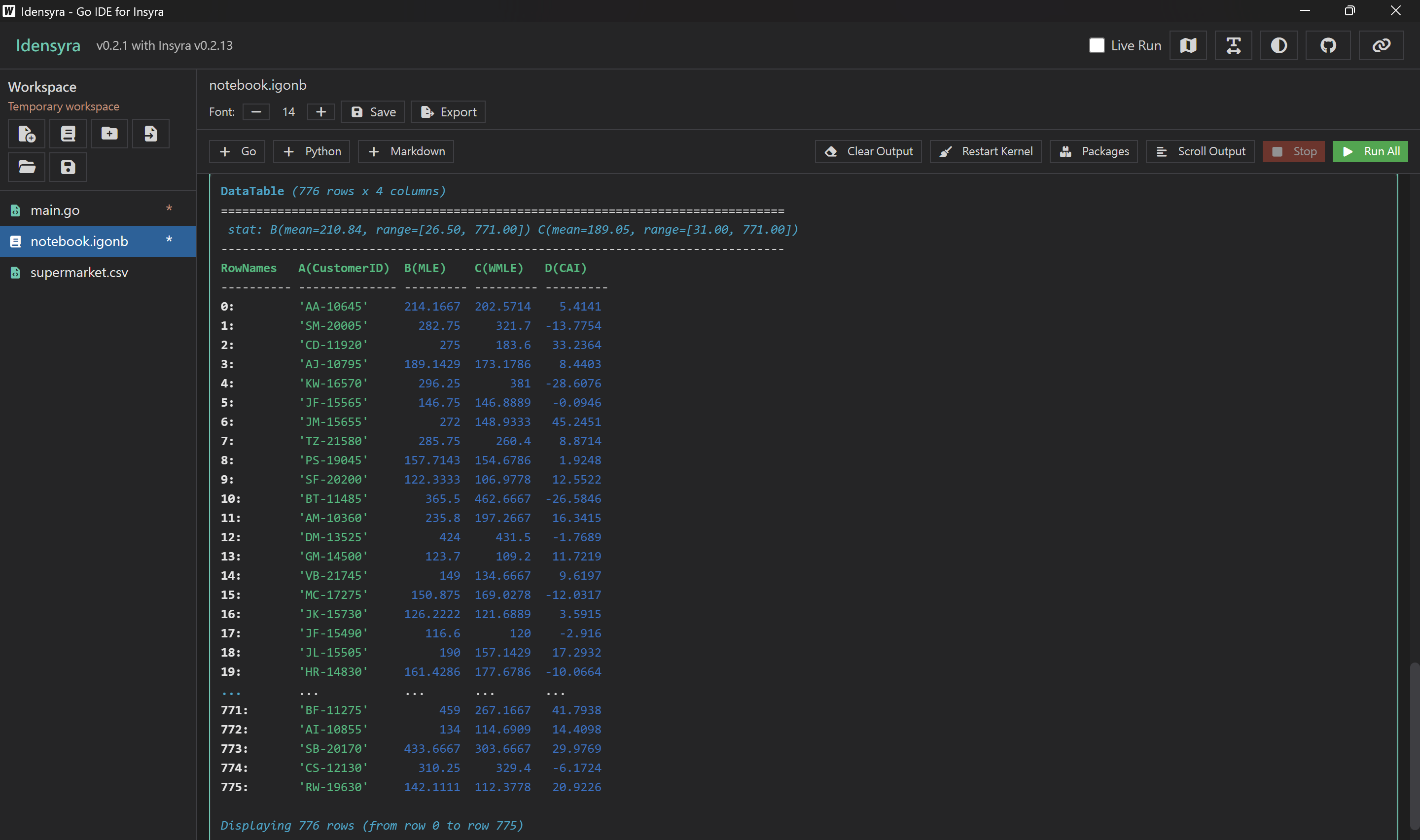
然後我們後續就可以根據 CAI 把顧客分成漸趨靜止、穩定和漸趨活躍,顧客的購買行為趨勢一目了然。
本篇文章使用的 Insyra 版本:v0.2.13
Insyra 官網:https://insyra.hazelnut-paradise.com
Insyra 說明文件:https://hazelnutparadise.github.io/insyra
Insyra GitHub 儲存庫:https://github.com/HazelnutParadise/insyra