
小小商家一點靈的核心是利用 RFM 和 CAI 對顧客進行分群,這兩個指標到底是不是真的有效,關乎到這個系統在實務上的可行性。因此,我想使用實際資料來進行驗證。
資料準備
我們可以使用之前在畢業專題小札記04:顧客價值具象化!RFM、CAI 指標與 Insyra 中的實作中用過的資料:
資料集名稱:Supermarket
來源:kaggle
頁面網址:https://www.kaggle.com/datasets/eslamessam2025/supermarket
資料欄數:18
資料筆數:9800
為了驗證 RFM 和 CAI,我們要先把資料切成兩半,然後看後半部的結果有沒有符合前半部的預測。
這份資料的時間範圍是 2015 年到 2020 年 7 月,因此我把 2015 年 1 月 1 日到 2017 年12 月 31 日的資料當作前半部(in sample),2018 年之後當成後半部(out of sample)。
我發現用 Excel 直接把這份資料轉成 Excel 檔會有問題,有些資料會錯位,所以後來又用 Insyra 重新把 CSV 轉成 Excel:
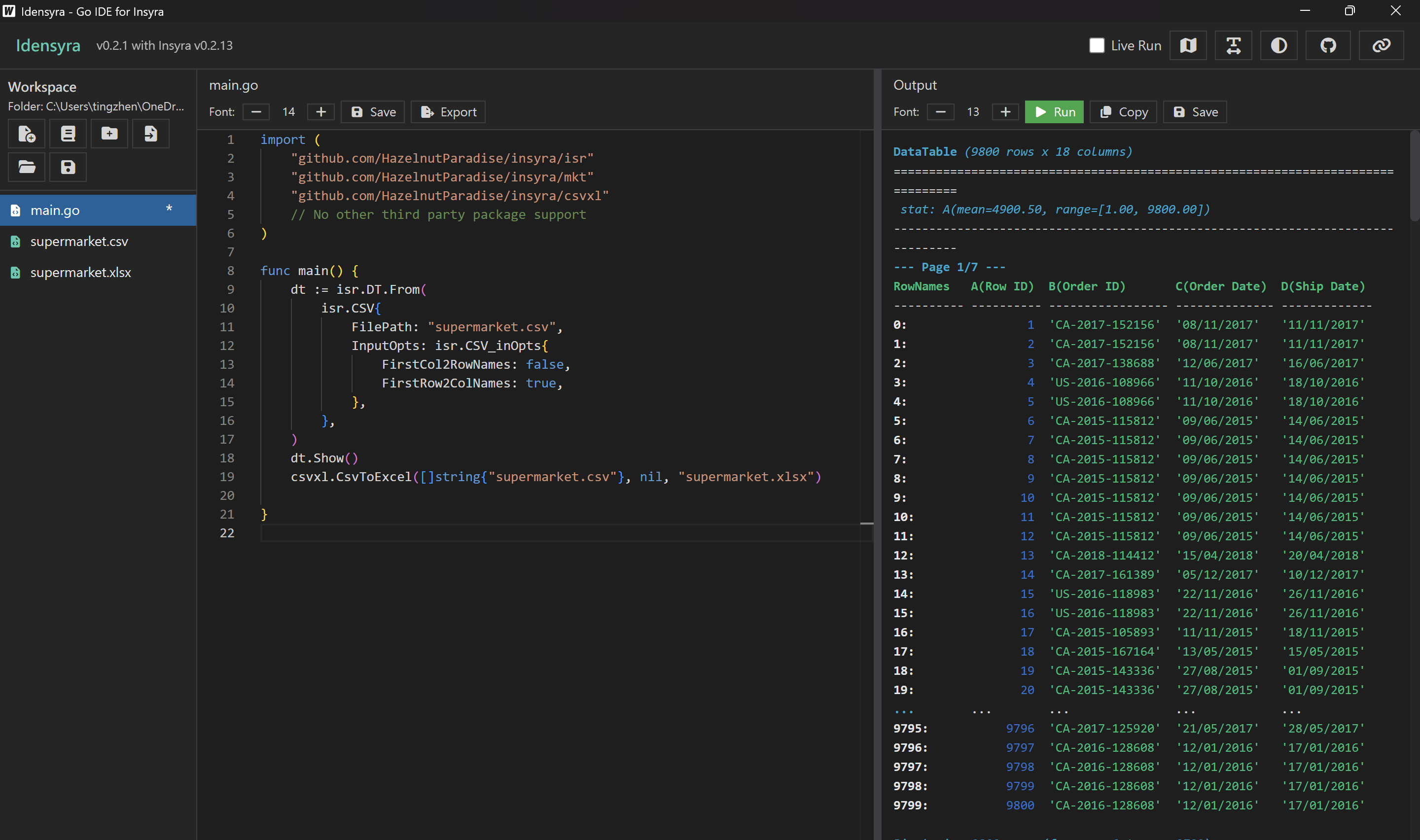
Excel 請加油。
RFM 驗證
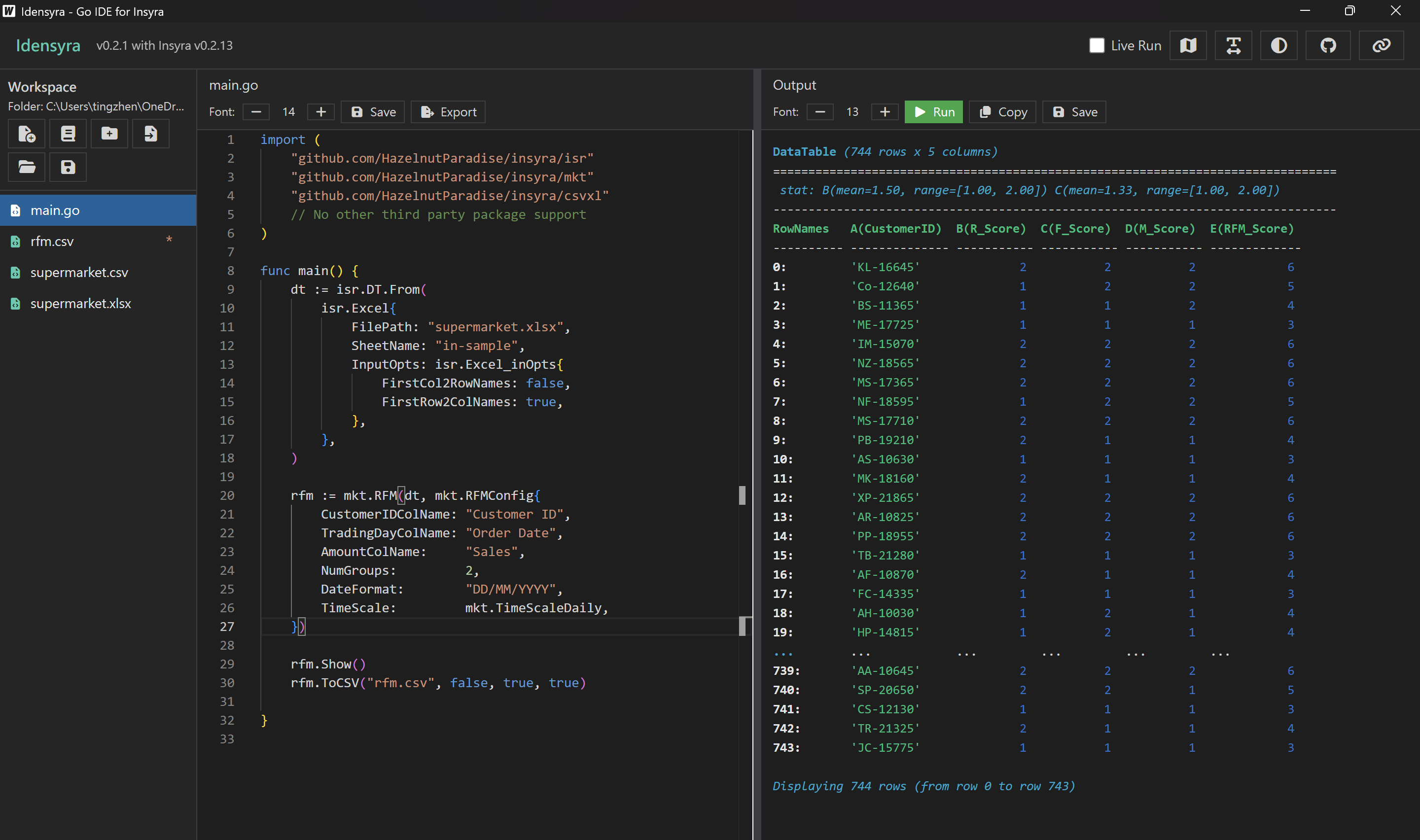
我首先要把前半部資料的 RFM 算出來。和小小商家一點靈一樣,R、F、M 都各分為兩組。
import (
"github.com/HazelnutParadise/insyra/isr"
"github.com/HazelnutParadise/insyra/mkt"
"github.com/HazelnutParadise/insyra/csvxl"
// No other third party package support
)
func main() {
dt := isr.DT.From(
isr.Excel{
FilePath: "supermarket.xlsx",
SheetName: "in-sample",
InputOpts: isr.Excel_inOpts{
FirstCol2RowNames: false,
FirstRow2ColNames: true,
},
},
)
rfm := mkt.RFM(dt, mkt.RFMConfig{
CustomerIDColName: "Customer ID",
TradingDayColName: "Order Date",
AmountColName: "Sales",
NumGroups: 2,
DateFormat: "DD/MM/YYYY",
TimeScale: mkt.TimeScaleDaily,
})
rfm.Show()
rfm.ToCSV("rfm.csv", false, true, true)
}
把計算出來的結果貼到 Excel,然後加上分群和會員類型,公式分別為:
RFM_Group
=B2&C2&D2Type
=SWITCH(F2,"111","需開發會員","112","重要挽留會員","121","一般保持會員","122","重要保持會員","211","流失會員","212","重要發展會員","221","一般價值會員","222","重要價值會員","")分法跟小小商家一點靈是一樣的。
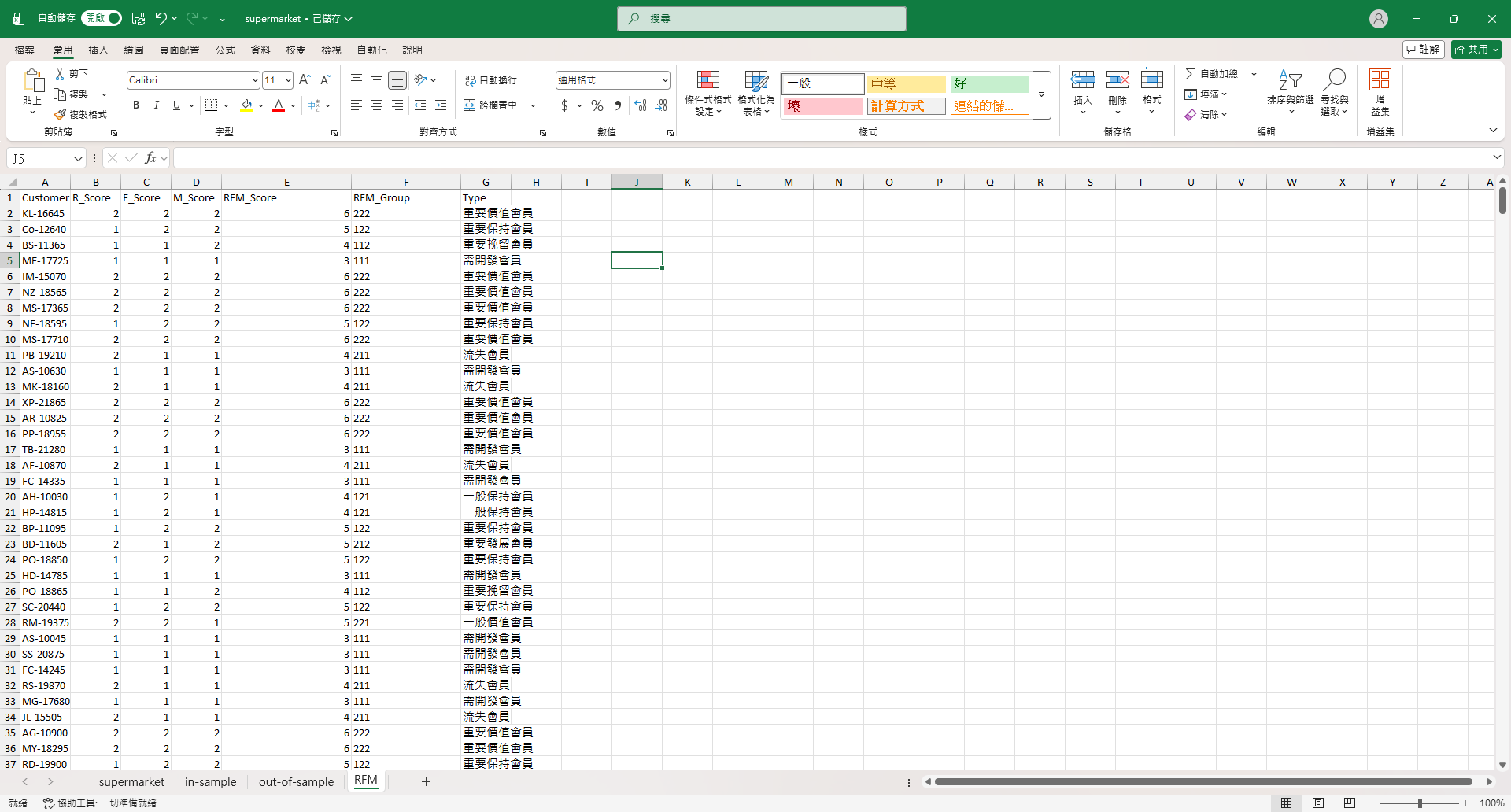
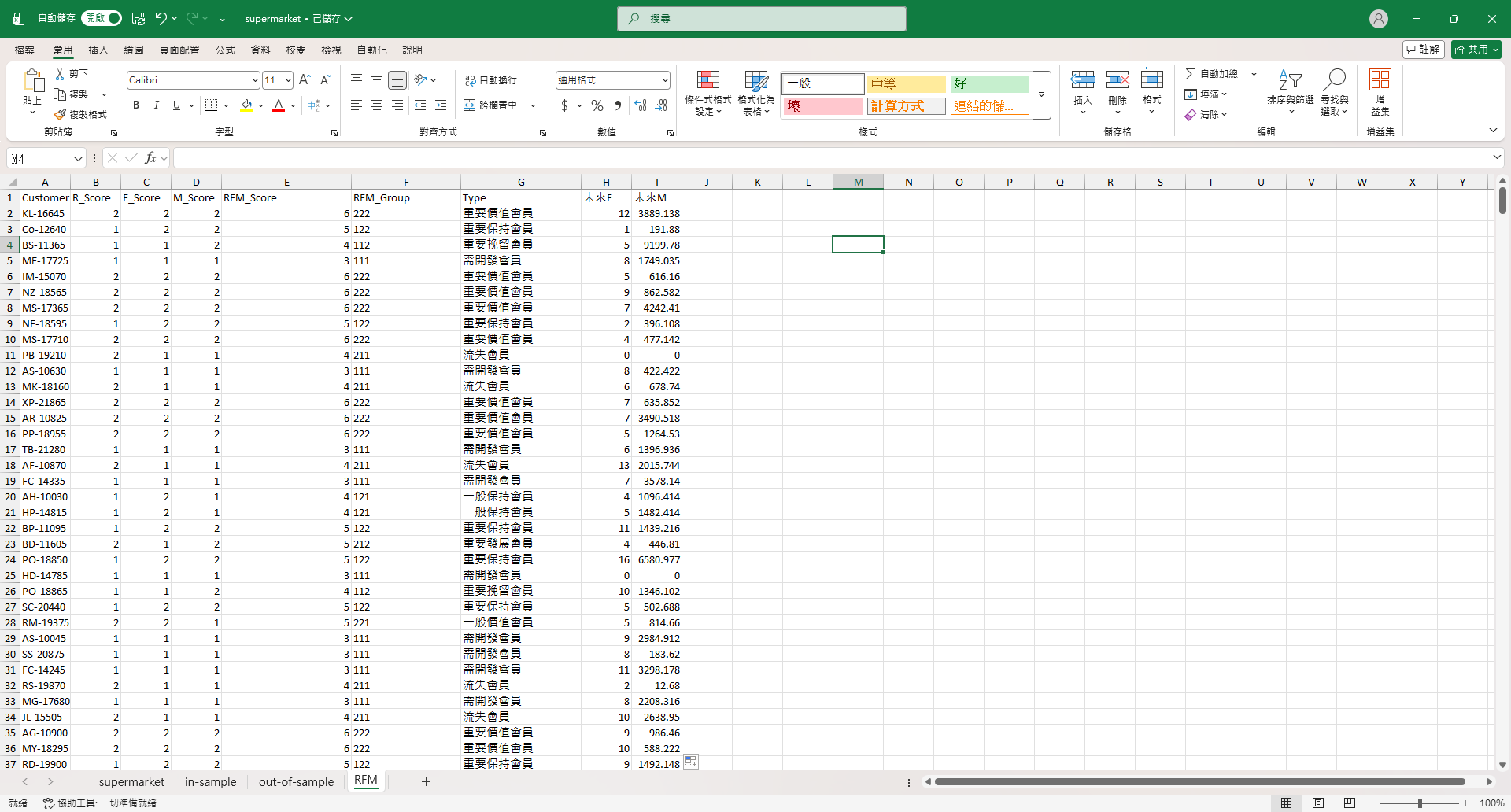
接著我加入兩欄,「未來F」和「未來M」,分別是後半部資料中對應顧客的交易次數和總金額。
未來F
=COUNTIF('out-of-sample'!G:G,RFM!A2)用 COUNTIF 查出後半部資料中每位顧客出現次數,就是交易次數。
未來M
=SUMIF('out-of-sample'!G:G,RFM!A2,'out-of-sample'!S:S)用 SUMIF 計算後半部資料中對應顧客的消費總額。
One-Way ANOVA
RFM 會員類型是類別變數,未來 F 和未來 M 是連續變數,所以我可以把會員類型當作自變數、未來 F 和未來 M 當作依變數,來檢驗不同會員類型在未來F、未來M 上是否有顯著差異。
以下使用 SPSS 來做分析。
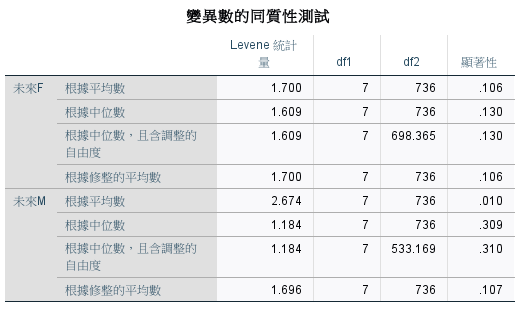
各會員類型的未來 F 變異數同質,但是未來 M 不同質。
未來 F
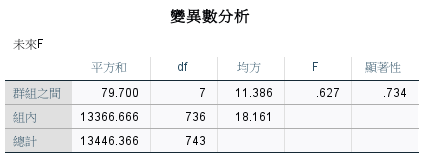
從未來 F 的變異數分析來看,各會員類型之間的未來交易次數並沒有顯著🥲。
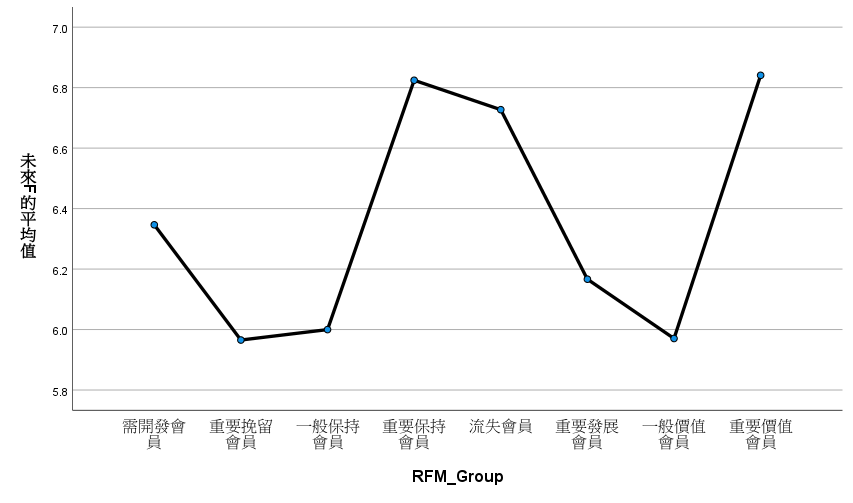
雖然各組差異不大,但從平均值圖形來看,重要價值會員的確是未來交易次數最多的,重要挽留會員確實後來的交易次數較少,其它組則看不出來在幹嘛,呵呵😅。
未來 M
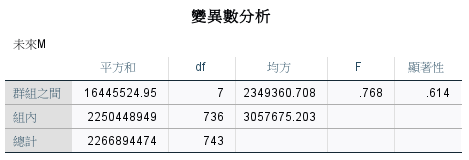
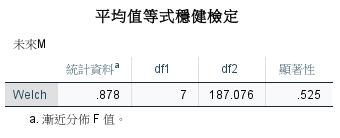
翻車了!未來 M 也沒有顯著🤡。
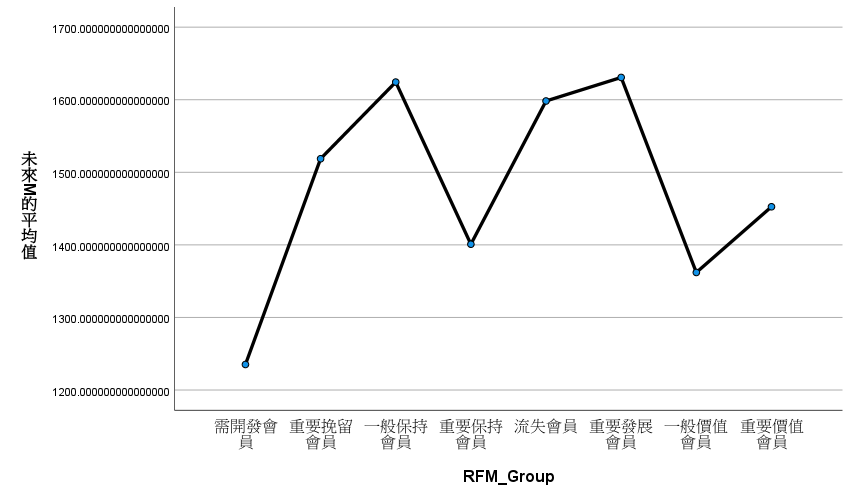
重要挽留會員、重要發展會員金額確實較高,其它我就看不太懂了。
CAI 驗證
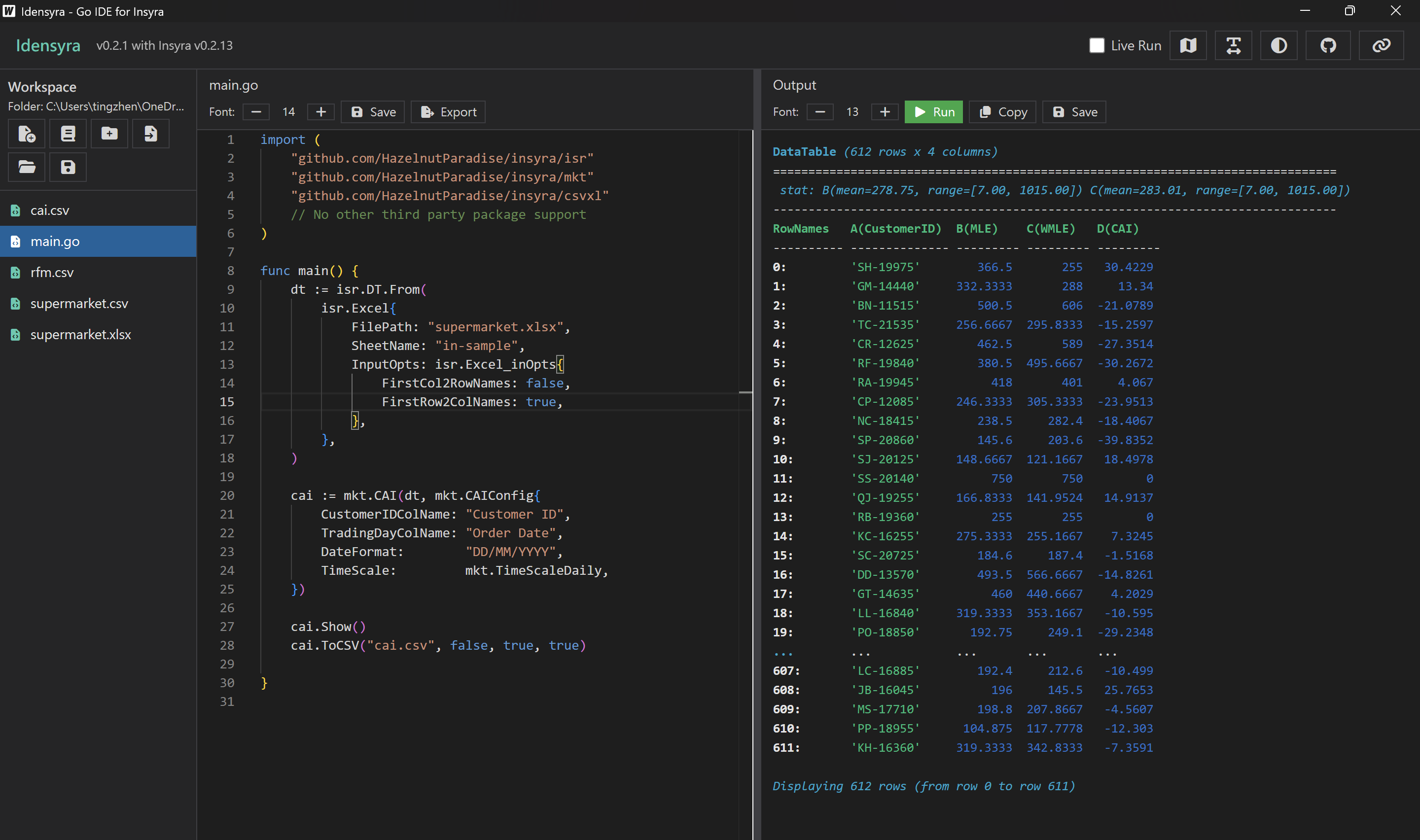
一樣拿 in-sample 的資料去算 CAI。
import (
"github.com/HazelnutParadise/insyra/isr"
"github.com/HazelnutParadise/insyra/mkt"
"github.com/HazelnutParadise/insyra/csvxl"
// No other third party package support
)
func main() {
dt := isr.DT.From(
isr.Excel{
FilePath: "supermarket.xlsx",
SheetName: "in-sample",
InputOpts: isr.Excel_inOpts{
FirstCol2RowNames: false,
FirstRow2ColNames: true,
},
},
)
cai := mkt.CAI(dt, mkt.CAIConfig{
CustomerIDColName: "Customer ID",
TradingDayColName: "Order Date",
DateFormat: "DD/MM/YYYY",
TimeScale: mkt.TimeScaleDaily,
})
cai.Show()
cai.ToCSV("cai.csv", false, true, true)
}
CAI 的計算結果複製到 Excel 之後加一欄「購買行為趨勢」,算法和小小商家一點靈在 Google Sheets 上的一樣:
=IF(D2="", "", IF(D2<(0-STDEVA(D:D)), "沉寂", IF(D2>(0+STDEVA(D:D)), "活躍", "固定")))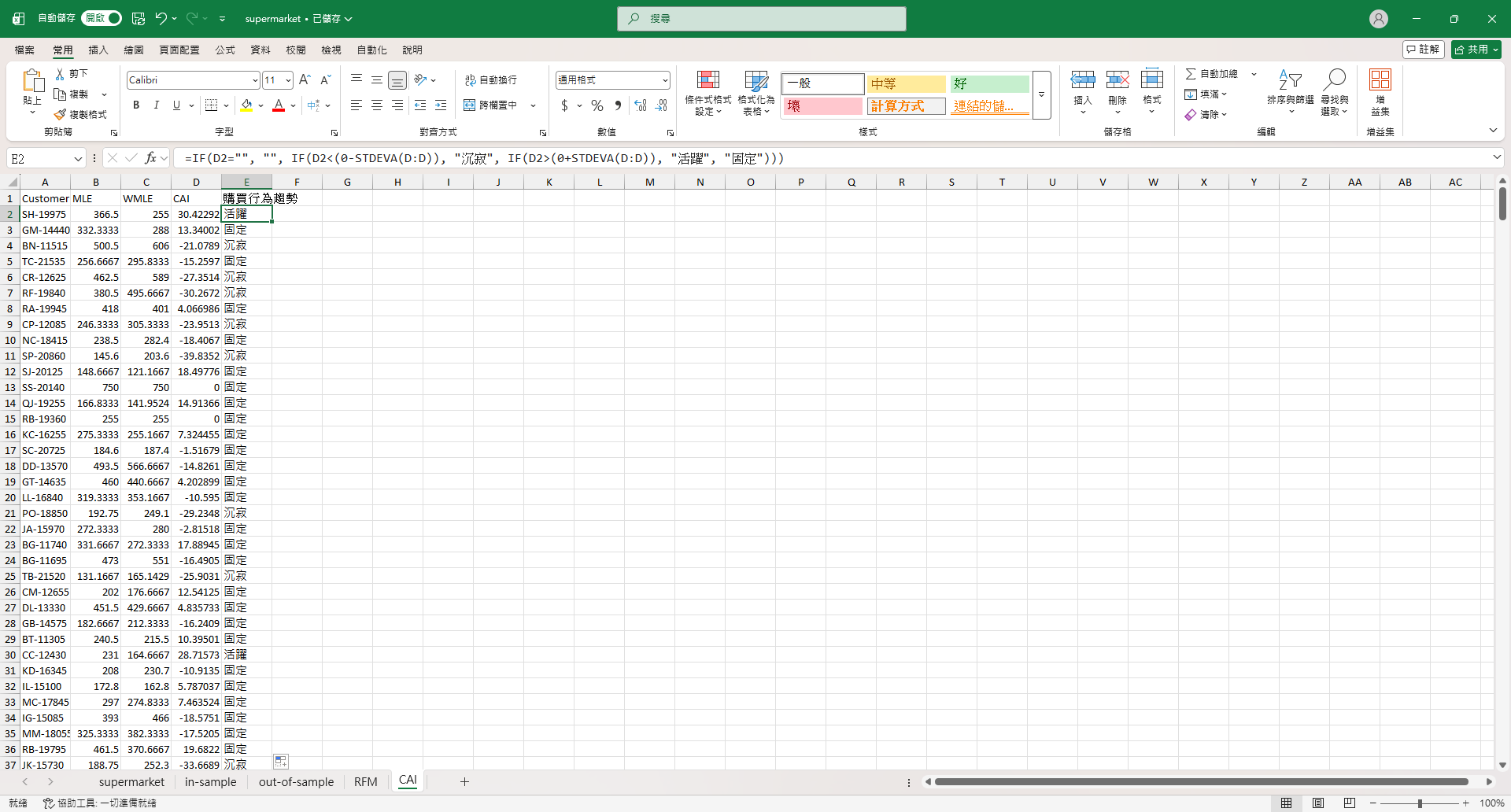
然後一樣加入未來F和未來M。
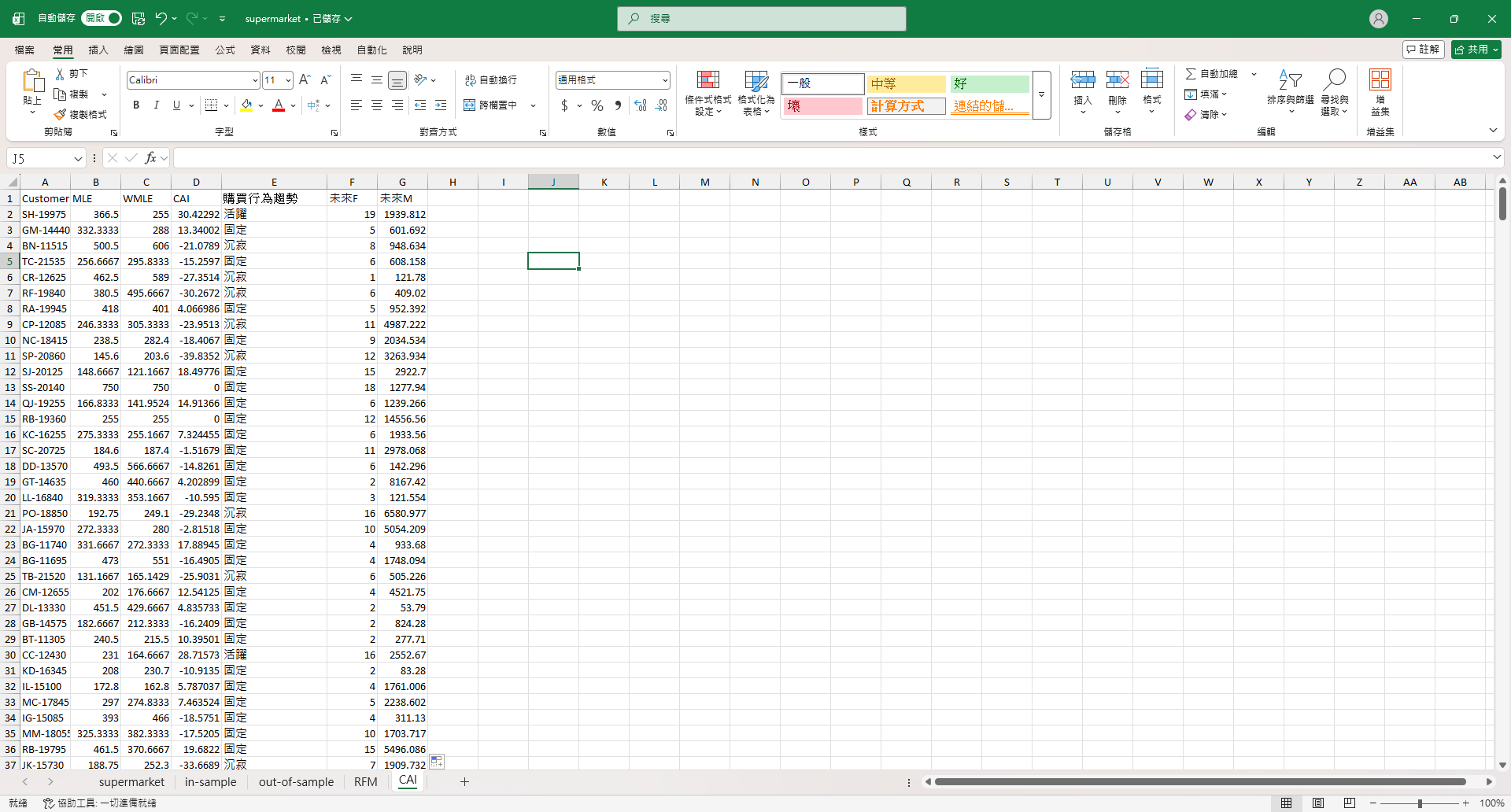
為了要用 SPSS 做 ANOVA 分析,我要把行為趨勢轉成編碼。
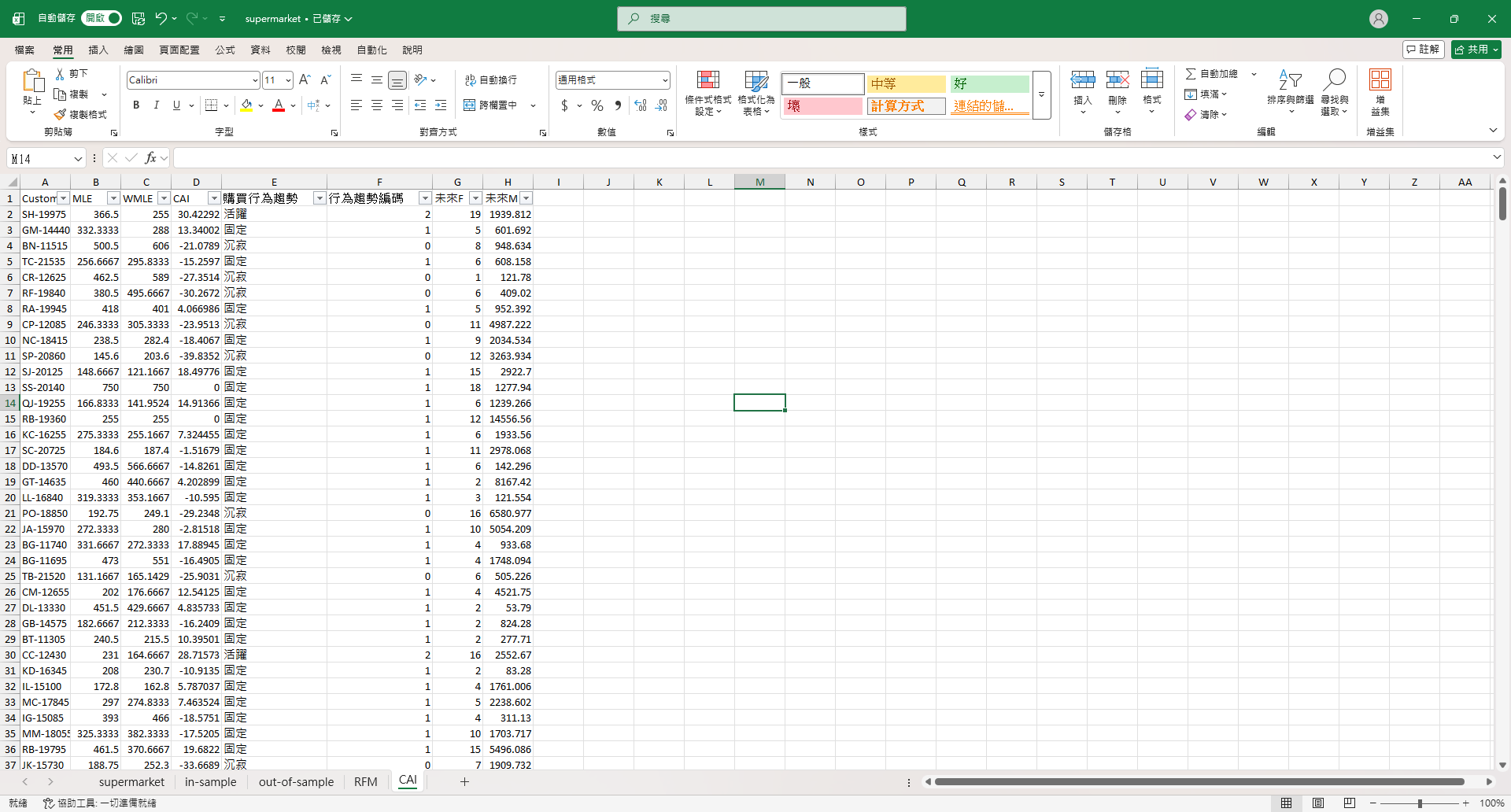
One-Way ANOVA
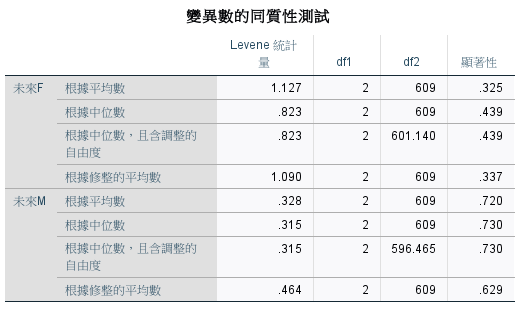
各種購買行為趨勢類型的未來 F 和 未來 M 變異數不同質。
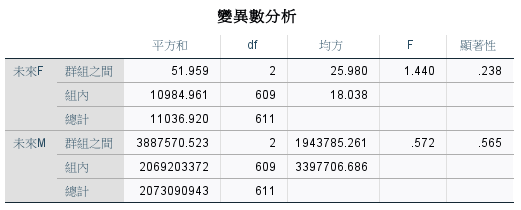
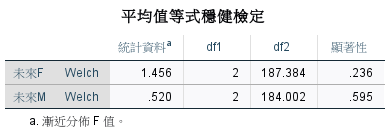
各群之間差異不顯著😭😭。
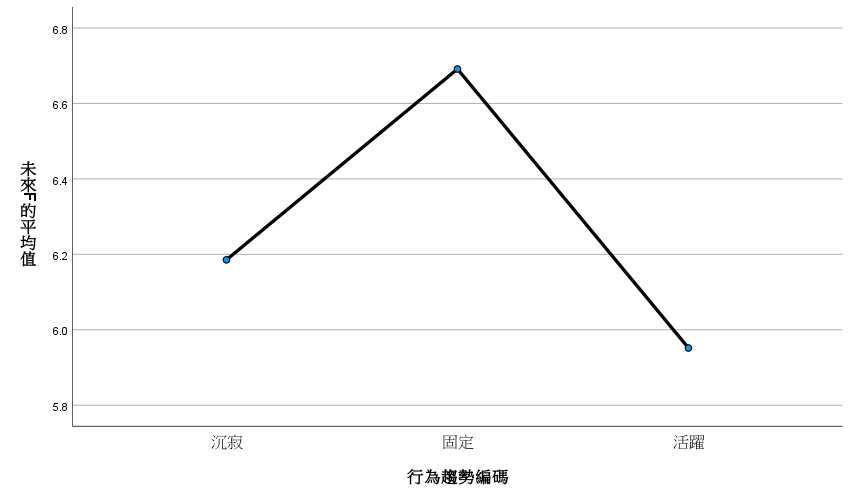
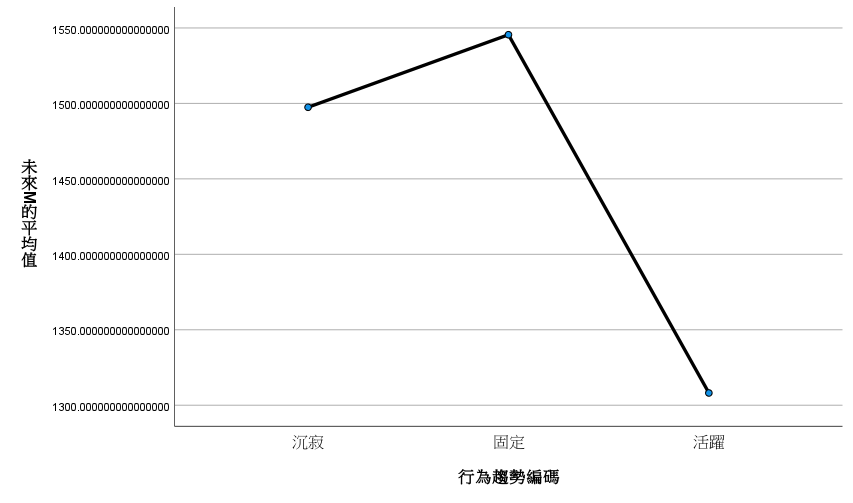
平均值圖形看起來也很詭異,原以為越來越活躍的顧客,後來交易次數和金額竟是最少。反而是行為固定的,交易次數和金額都最高。
結論
小小商家一點靈所使用的兩種分群方法都無法達到統計上的顯著,我一時之間不知道結論怎麼下了。
我乾脆包一包去賣章魚燒好了。
本篇文章使用的 Insyra 版本:v0.2.13
Insyra 官網:https://insyra.hazelnut-paradise.com
Insyra 說明文件:https://hazelnutparadise.github.io/insyra
Insyra GitHub 儲存庫:https://github.com/HazelnutParadise/insyra