上次我試圖用 Kaggle 上的超市銷售資料來驗證 RFM 和 CAI 模型,結果大翻車。
經過與指導老師討論後,決定找餐飲業的資料來試試,希望這次會得到比較漂亮的結果。
新的範例資料
我找到的幾個範例資料集如下:
總共四份 CSV 和一份 SQL,全都是餐飲業的資料。
窺探資料的樣貌
接著我要先看看這些資料長怎樣、有沒有遺漏值之類的。但我懶得自己做,所以叫 Claude 用 Insyra CLI 來幫我做:
/use-insyra-cli 幫我看看這幾份資料 有哪些欄位 是否需要清理 如果需要清理就清理好
然後給我每一份資料的summary .isr檔 與清理完的資料
不要覆蓋原檔
summary要包含有幾筆資料 資料的時間範圍等等
要去讀檔案實際內容 不要只看檔名這部分是用 Claude Code + 我自己做的 use-insyra-cli skill。
他看起來還是用了 Python,不過無所謂。
各資料集摘要
1. Restaurant Orders Dataset (June–July 2025)
550 筆 / 16 欄 / 2025-06-01 ~ 2025-06-30
無需清理 — TotalPrice 全部驗算正確,無缺失、無重複
ServerName / TableNumber 使用
-代表外送/外帶(非缺失值)
2. Restaurant Sales and Customer Behaviour
200 → 189 筆 / 13 欄 / 2024-01-01 ~ 2024-03-31
已修正:刪除 11 筆 "Unknown Customer";修正 21 筆 Total_Amount 計算錯誤(最嚴重如 ORD1110:Total 寫了 18000,實為 1600);補算 6 筆缺失 Total;填入 8 筆缺失 Order_Mode、11 筆缺失 Food_Category
新增
Data_Quality_Flag欄位標記每筆異常類型
3. Restaurant Sales-Dirty Data for Cleaning Training
17,534 → 17,104 筆 / 9 欄 / 2022-01-01 ~ 2023-12-31
刻意植入的髒資料集(用於教學);刪除 430 筆 Item+Price+Qty 全缺的無效列;1,328 筆缺品項 → 填 "Unknown";943 筆缺付款方式 → 填 "Unknown";446 筆缺 Price → 由 Total÷Qty 反推
新增
Data_Quality_Flag欄位
4. Takeaway Dataset for Predictive Analytics
10,000 筆 / 15 欄 / 2024-01-16 ~ 2025-01-15
無需清理 — 全部欄位完整,無缺失、無重複,數值範圍合理
5. Restaurant Sales and Customer Analysis (.sql)
這是 SQL Server DDL 腳本,非資料集(UTF-16 編碼)
包含 RestaurantDb 資料庫結構:tblCustomer、tblFactorID、tblFactorDetails、tblFoodsDescription 等表,以及 3 個 UDF 和 1 個庫存 View
疑為伊朗餐廳管理系統(View/UDF 名稱含波斯文)
無對應 _cleaned.csv;summary .isr 提供完整 schema 說明
Restaurant Sales and Customer Analysis 裡面只有 Schema,那我不管他了,用其他四份資料。
把資料切成兩半
為了驗證 RFM 和 CAI 模型,我需要把每份資料都切成兩半。
/use-insyra-cli 把清理好的資料載入insyra 分別依據時間排序 然後各自切成兩半
切分點正常一點 不要切在奇怪的時間切分結果
流程說明:CCL 的 filter 不支援字串日期的大小比較(< / >),所以用 Python 排序並加了 split_half 欄位(0=前半、1=後半),insyra 再 filter 這個數字欄位切出兩半並存檔。4 個 .isr 腳本都放在 isr/ 資料夾,可直接 insyra run 重跑。
看起來 Insyra 還有需要改進的地方。
計算 RFM
接著要使用前半部的資料計算 RFM。
/use-insyra-cli使用每份資料集前半部的資料算顧客RFM 群數兩群 類似以下這樣
rfm := mkt.RFM(dt, mkt.RFMConfig{
CustomerIDColName: "Customer ID",
TradingDayColName: "Order Date",
AmountColName: "Sales",
NumGroups: 2,
DateFormat: "DD/MM/YYYY",
TimeScale: mkt.TimeScaleDaily,
})
然後匯出每份資料集的RFM計算結果檔案4 份 RFM 結果全部完成,存在 rfm/ 資料夾:
每筆欄位:CustomerID, R_Score, F_Score, M_Score, RFM_Score(NumGroups=2,分數範圍 R/F/M 各 1–2,RFM_Score 為三者加總)。
Orders 和 Takeaway 的日期欄位含時間戳,RFM 只需日期,所以事先用 Python 截掉時間再送進去。
計算 CAI
然後是 CAI。
/use-insyra-cli /insyra 使用每份資料集前半部的資料算顧客CAI 類似以下這樣
cai := mkt.CAI(dt, mkt.CAIConfig{
CustomerIDColName: "Customer ID",
TradingDayColName: "Order Date",
DateFormat: "DD/MM/YYYY",
TimeScale: mkt.TimeScaleDaily,
})
然後匯出每份資料集的CAI計算結果檔案4 份 CAI 結果全部完成。順便注意幾個有趣現象:
Orders CAI 只有 4 位顧客 — 因為單月資料(6/1–6/15)裡能計算 CAI 的顧客必須有多筆交易紀錄,大部分顧客只來過一次就無法算出活躍度趨勢。
Behaviour CAI 全部 CAI = 0 — 資料集每位顧客在 H1(1月–2/15)幾乎只出現 1–2 次,間隔完全相等,所以 MLE = WMLE,差值為 0,代表這份資料不太適合做 CAI 分析。
Dirty Data 和 Takeaway 才是比較有意義的結果,顧客有足夠的回購頻率讓 CAI 能反映活躍趨勢(正值 = 活躍度上升、負值 = 活躍度下降)。
欄位說明:CustomerID, MLE(平均購買間隔), WMLE(加權平均間隔,近期權重較高), CAI(= (MLE−WMLE)/MLE × 100%)
合併成 Excel
為了方便後續驗證,我想把 Raw Data、RFM、CAI 合成一份 Excel 檔案。
由於 Orders 和 Behaviour 沒有計算出有意義的 CAI 結果,我接下來將只用 Dirty Data 和 Takeaway 兩個資料集。
/insyra/use-insyra-cli幫我把 Dirty Data 和 Takeaway兩份資料集 各自的raw cleaned 前段 後段 rfm cai分別合併成一份excel完成,兩份 Excel 都在 rfm/ 資料夾:
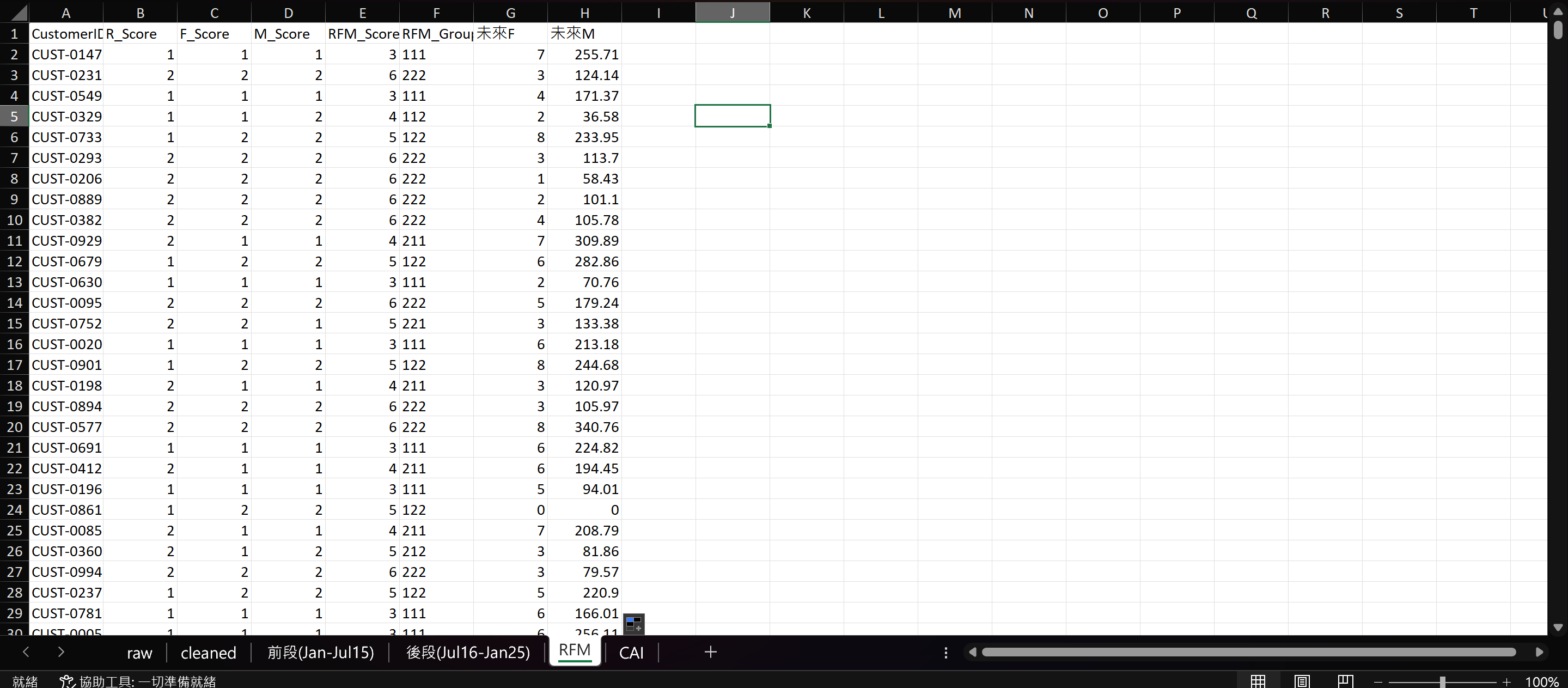
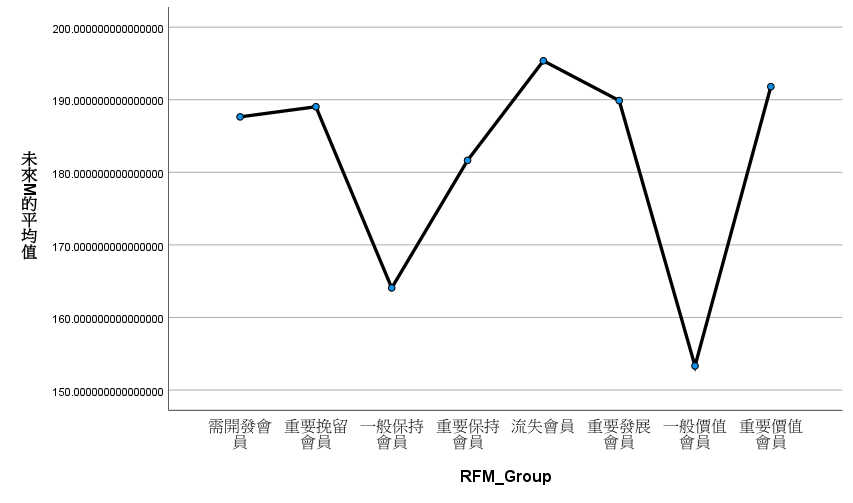
我要在兩份資料集的 RFM 工作表中加入「RFM_Group」。
=B2&C2&D2再加入「未來F」和「未來M」。
=COUNTIF('後段(2023)'!B:B,A2)=SUMIF('後段(2023)'!B:B,RFM!A2,'後段(2023)'!G:G)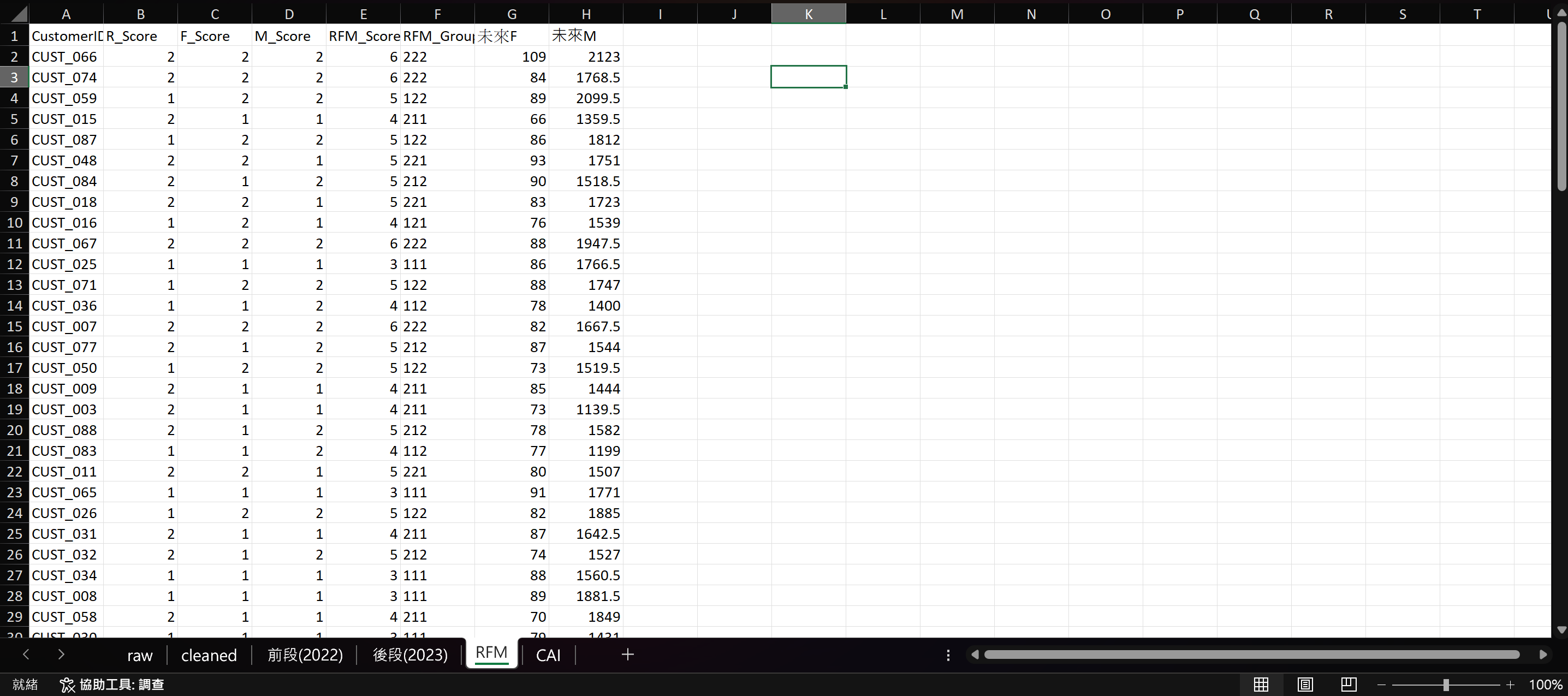
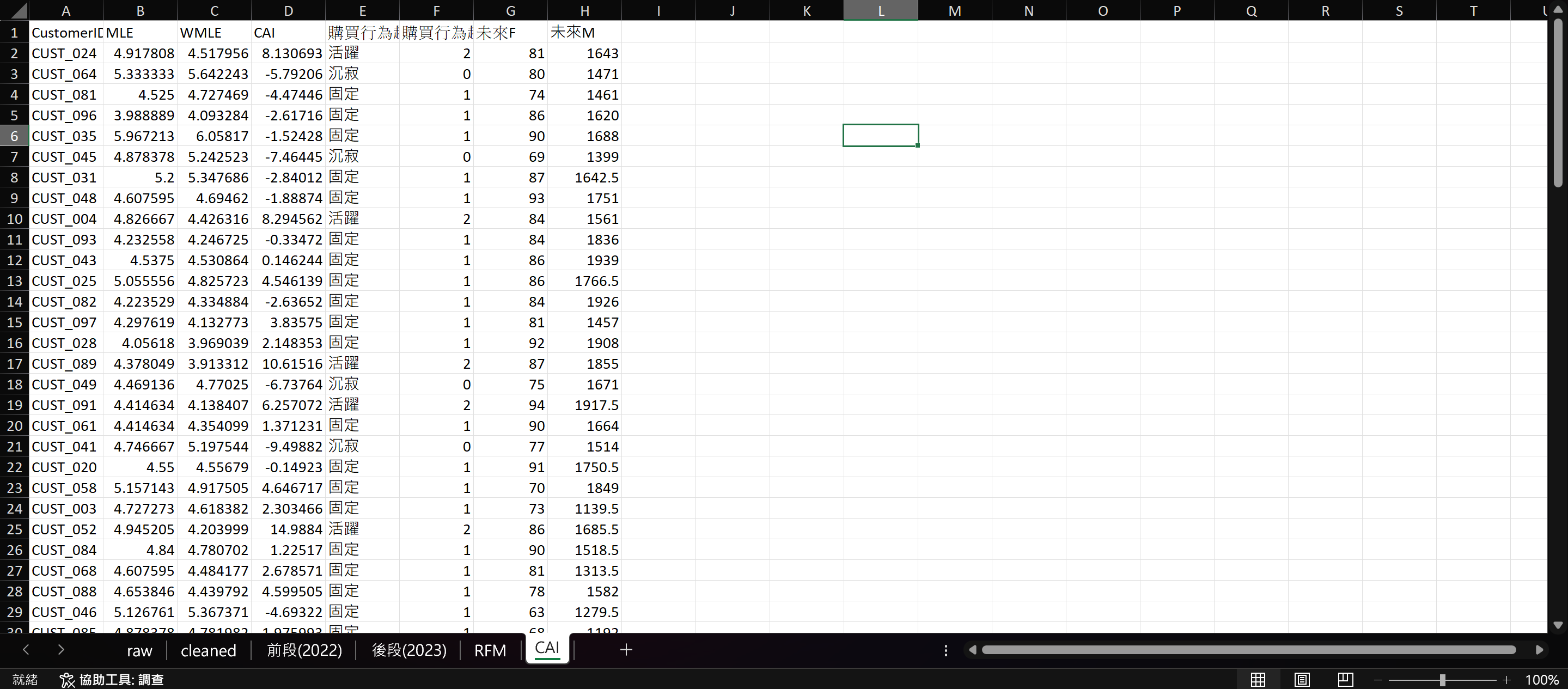
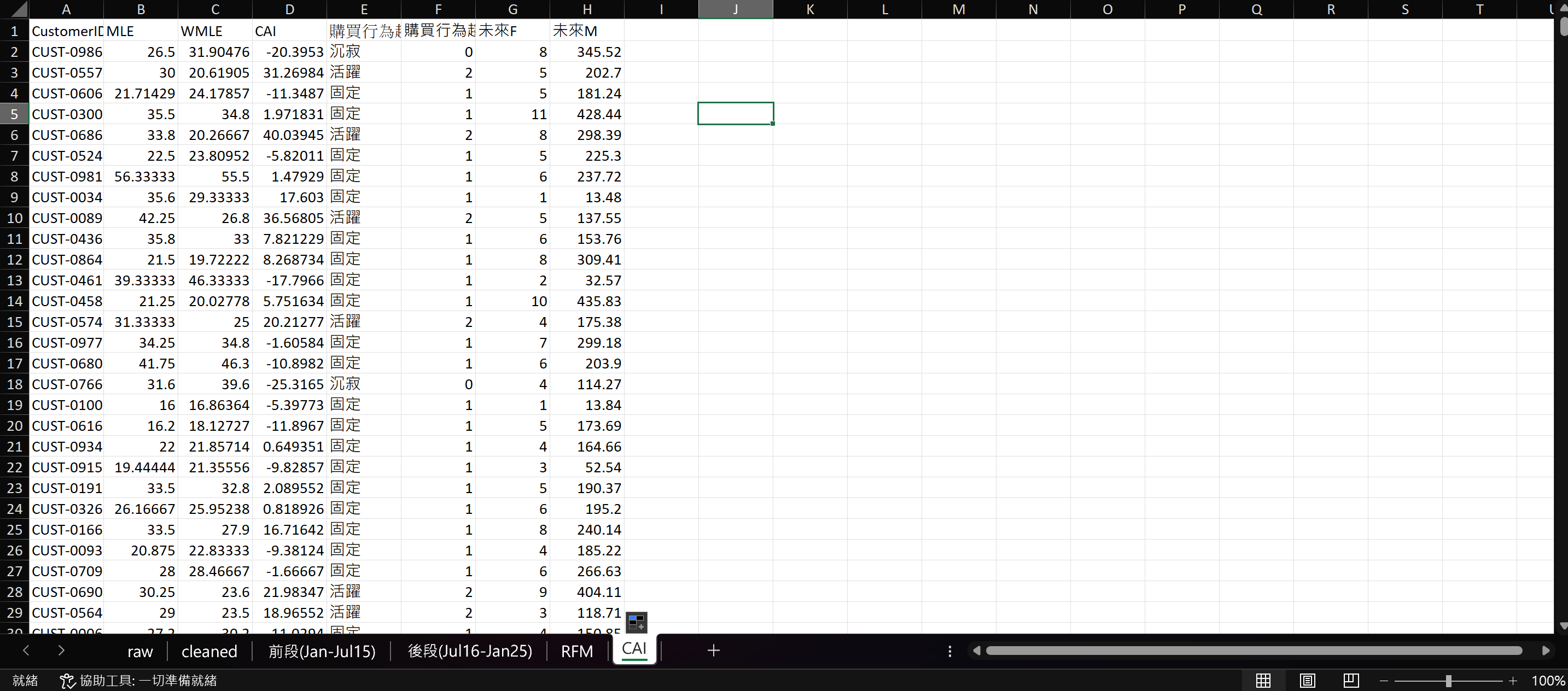
接著我要在兩份資料集的 CAI 工作表加上一欄「購買行為趨勢」和「購買行為趨勢編碼」。
=IF(D2="", "", IF(D2<(0-STDEVA(D:D)), "沉寂", IF(D2>(0+STDEVA(D:D)), "活躍", "固定")))=SWITCH(E2,"活躍",2,"固定",1,0)一樣再加入「未來F」和「未來M」。
驗證 RFM
DirtyData
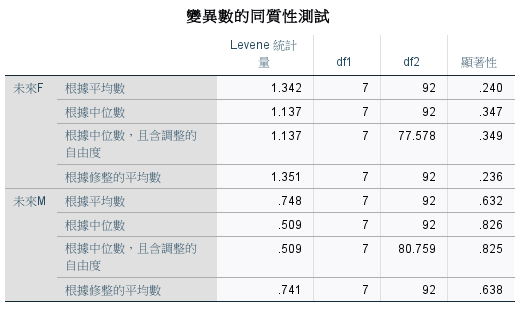
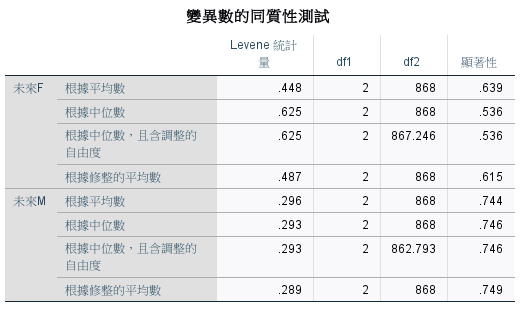
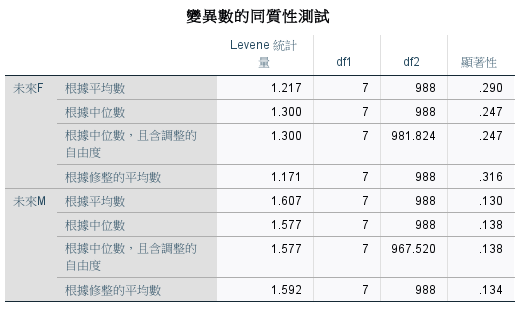
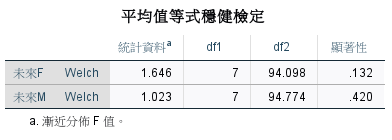
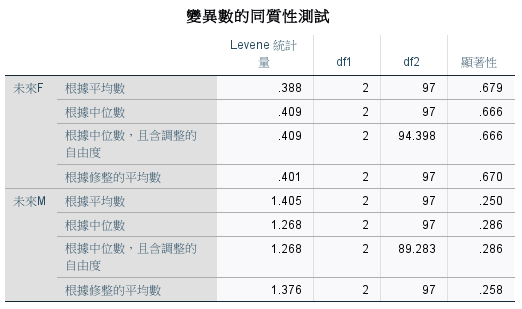
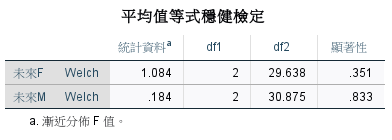
各種購買行為趨勢類型的未來 F 和 未來 M 變異數不同質。
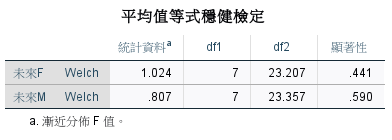
各群之間的差異沒有顯著。
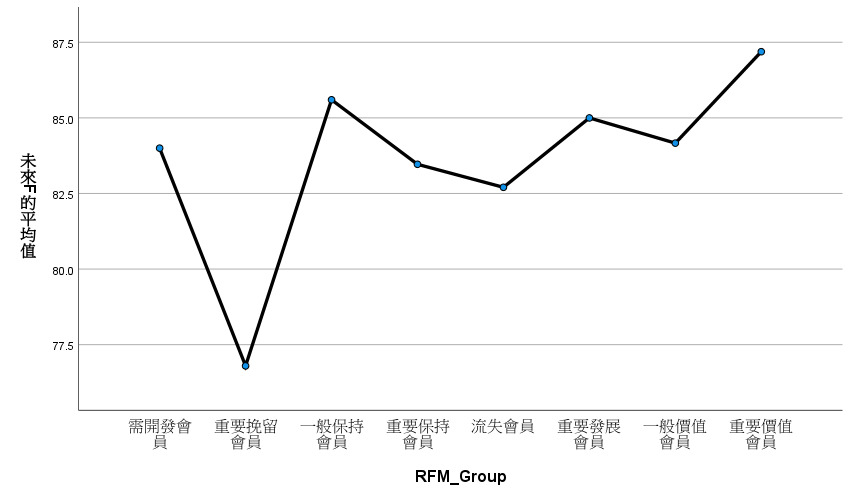
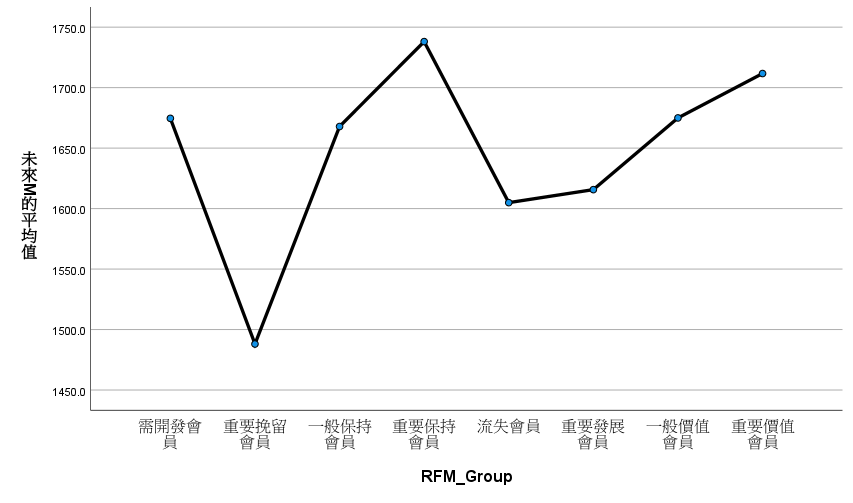
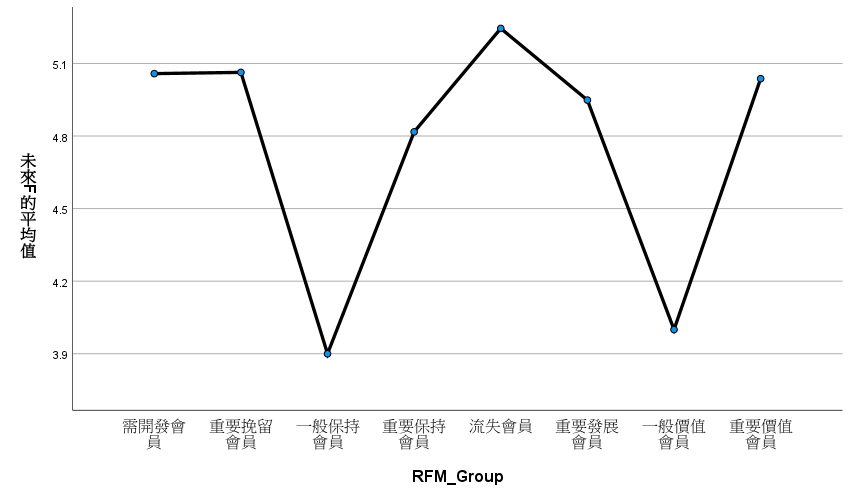
Takeaway
也都沒有同質。
組間差異沒有顯著。
驗證 CAI
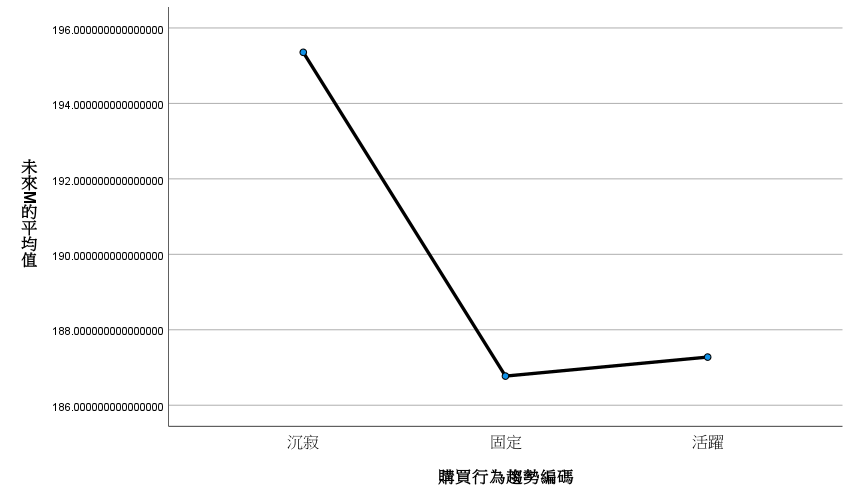
DirtyData
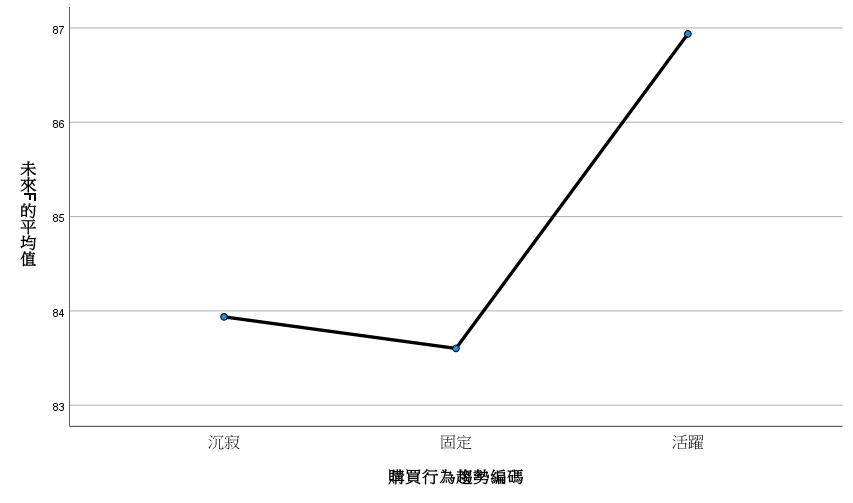
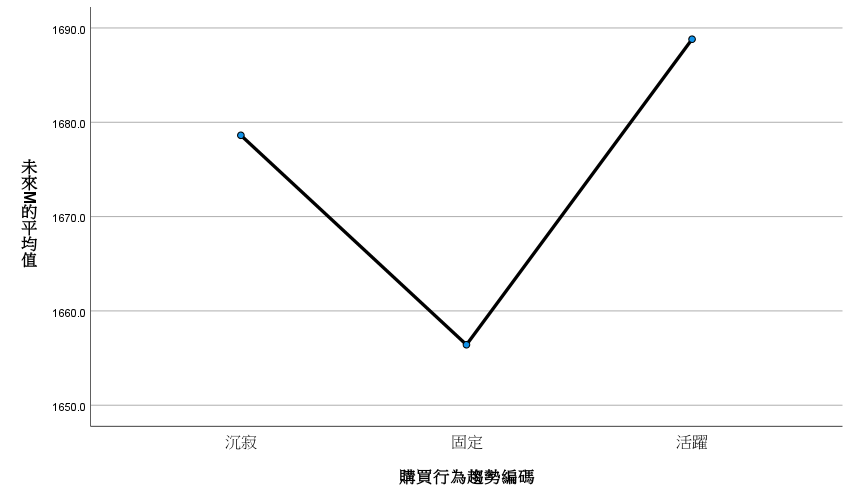
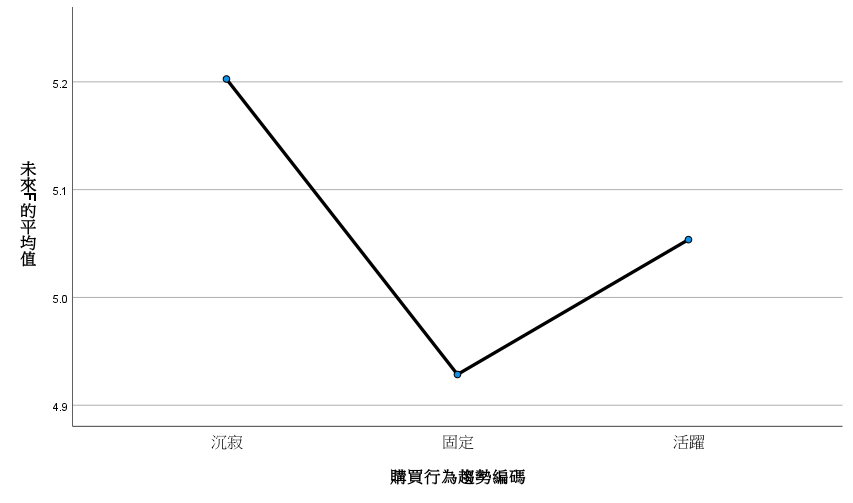
Takeaway